AI Training Hardware Buyers Guide
Once a development pipeline has been established and an AI model is ready for production, the next step is to train the AI model. The training phase requires far more GPU and storage resource than during development, as many iterations will be needed. Training is therefore the most expensive part of any AI project. Training requires at minimum a multi-GPU server, supported by fast storage and connected via high-throughput, low-latency networking. If these three component parts of your AI infrastructure aren’t matched or optimised, productivity and efficiency will be impacted - the fastest GPU-accelerated super computer will be a waste of money if connected to storage that cannot keep its GPUs 100% utilised.

This guide takes you through the myriad of AI training hardware options, explaining their suitability for different projects and their ability to scale - including small language models (SLMs), large language models (LLMs), vision language models (VLMs), generative AI, agentic AI and physical AI models. It’s also worth noting that many of these servers are suitable for inferencing large AI models - check out our AI Inferencing Hardware Buyers Guide for more information.
Your AI Project
The training of an AI model is always preceded by the project scoping, data preparation and AI development phases, as illustrated below.
Problem Statement
Project scope and high level ROI
Data Preparation
Classification, cleaning and structure
Model Development
Education and resource allocation
Model Training
Optimisation and scaling
Model Integration
Inferencing and deployment
Governance
Maintenance and compliance
It may not be immediately obvious, but ensuring your project scope is realistic and achievable has a large impact on what AI training hardware you’ll ultimately require. These early stages are crucial to get right - you can learn more by reading our AI Project Planning Guide and our AI Development Hardware Buyers Guide.
AI Model Training
Your AI model development phase will likely have involved using frameworks or optimised foundation models (FMs) to save time and effort when building your AI pipeline - all available in the NVIDIA AI Enterprise (NVAIE) software platform. This is optimised for NVIDIA GPUs and included in DGX Spark and DGX Station GB300 development platforms; and the DGX Servers discussed further down this guide. NVAIE is also available on subscription for the non-DGX servers too.
NVAIE provides end-to-end implementation of AI projects such as medical imaging, autonomous vehicles, avatars, drug discovery, generative AI, agentic AI, physical and robotics; scaling across development, training and inferencing platforms seamlessly.

The frameworks or FMs used in development will have a significant impact on initial model size when you get to the training phase. If you started with a single GPU workstation, then training may be possible on a single multi-GPU server, however if your AI model was developed on multi-GPU workstations then chances are that multiple multi-GPU servers will be required to train it. It is therefore key to understand the relative size of models, how they might scale and the GPU hardware that will be capable of handling their training. Just for context, between the 1950s and to 2018, AI model size grew by seven orders of magnitude (from 000’s to 30M) - from 2018 to 2022 alone, it has grown another four orders of magnitude (from 30M to 20B). Today 400B parameter models are not uncommon and ChatGPT-4 is rumoured to have 1.8T.
| Type of AI Model | Typical Use Case | Parameters | Initial Dataset Size | Typical Server(s) Required |
|---|---|---|---|---|
| SLMs | Limited scope chatbots / NLP / On-device applications | 100M - 7B | 1-8GB | Single, multi-GPU PCIe server |
| LLMs | Content creation / advanced chatbots / Real-time translation | 7B - 20B | 10-15GB | Single, multi-GPU SXM server |
| Generative AI | Advanced content creation / Personalised experiences / Drug Discovery | 20B - 70B | 20-40GB | Multiple, multi-GPU SXM servers |
| Agentic AI / VLMs | Personalised interactions / Data-driven insights / Autonomous vehicles | 70B - 200B | 60-150GB | GPU server cluster |
| Physical AI | Robotics / Digital Twins | 200B - xT | 200-750GB | GPU server cluster |
It is worth clarifying that this table is for guidance only - absolute size (in GB) of any model is determined by the number of parameters and the size of each parameter. Similarly, there will be small agentic AI models if their function is very focused and there will be very large LLMs if translation of many languages is the goal. It is also worth pointing out that the dataset size mentioned is the likely final size, so you need to consider capacity for numerous versions and many iterations before reaching the final model.
AI Hardware
The following AI training hardware options are compared and discussed in light of the model sizes above, offering recommendations and advice about the most suitable option for various scenarios. However, as previously stated, thorough planning and scoping phases will lead to much more accurate provisional model sizes and better insight into development hardware and ultimately, training hardware choice.
Traditional AI servers are built around the industry-norm of one or more x86 CPUs (either AMD or Intel) plus multiple NVIDIA GPUs, in either PCIe or SXM embedded form factor. The major benefit of PCIe cards is that as a well-established system architecture over decades, such systems are extremely cost-effective and very easy to upgrade. In contrast, SXM modules are not upgradable, but support more advanced GPUs and larger VRAM capacities.
The downside of both these form factors is that the CPU and GPU have separate pools of memory, so NVIDIA has developed a superchip approach combining an Arm-based (non-x86) CPU with two embedded GPUs on a single module. This innovative architecture enables higher density servers and high-performance clusters, taking advantage of many CPUs and GPUs a in a single stack, with coherent memory shared across the processors.
Click the tabs below to explore these options, or contact our AI team for more information or advice.
3XS RTX PRO Servers

3XS RTX PRO Servers are based on NVIDIA-certified designs. Powered by NVIDIA RTX PRO Blackwell Server GPUs, they provide best-in-class performance across a wide range of workloads including visualisation and rendering, scientific computing and HPC, and small-scale AI. Designed for datacentre environments, 3XS RTX PRO Servers are fine-tuned by our hardware engineers and workload specialists for maximum performance and reliability.
NVIDIA Elite Partner
Scan has been an accredited NVIDIA Elite Partner since 2017, awarded for our expertise in the areas of deep learning and AI.

AI Optimised
Our in-house team includes data scientists who optimise the configuration and software stack of each system for AI workloads.

Trusted by you
Scan AI solutions are trusted by thousands of organisations for their AI training needs.

7 Days Support
Our technical support engineers are available seven days a week to help with any queries.
3 Years Warranty
3XS Systems include a three-year warranty, so if anything goes faulty we’ll repair or replace it.
Architecture
3XS RTX PRO servers support up to eight NVIDIA RTX PRO Blackwell Server GPUs - offering up to 768GB VRAM, alongside NVIDIA ConnectX-7 SmartNICs. An updated version is expected shortly featuring embedded ConnectX-8 SuperNICs acting as HCAs and PCIe switches. This powerful combination provides best-in-class performance of up to 32 PFLOPS of FP4 for AI with up to 1.2 trillion model parameters, and 3 PFLOPS of ray tracing in visualisation applications. Additionally, using multi-instance GPU (MIG), each GPU can be shared with up to four users, fully isolated at the hardware level.
A key selling point of RTX PRO Servers is that they are fully configurable, with a wide range of CPUs, RAM, networking, storage and software.

| GPU Specifications | |
|---|---|
| Name | RTX PRO 6000 Blackwell Server |
| Architecture | Blackwell |
| Bus | PCIe 5 |
| GPU | GB202 |
| CUDA Cores | 24,064 |
| Tensor Cores | 752 (5th gen) |
| RT Cores | 188 (4th gen) |
| Memory | 96GB GDDR7 |
| ECC Memory | ✓ |
| Memory Controller | 512-bit |
| MIG Instances | 4 |
| Confidential Computing | Supported |
| TDP | 600W |
| Thermal | Passive |
Relative Performance & Capability
A 3XS RTX PRO server configured with the maximum eight RTX PRO 6000 Blackwell Server Edition GPUs has an FP4 performance of 32 PFLOPS (quadrillion floating-point operations per second), which is adequate for many SLMs and LLMs with a specific focus.
It’s also worth noting that unlike most other AI hardware, RTX PRO Servers are also an ideal platform for demanding visualisation workloads such as rendering and digital twins. This is because they include dedicated RT cores that accelerate raytracing. In addition, they support both Linux and Windows Server operating systems, the latter being a crucial requirement for many visualisation applications.
The dual nature of RTX PRO Servers is a big benefit for businesses, because it means that rather than investing in dedicated AI and visualisation servers you can switch between the two workloads at will.
| System | 3XS RTX PRO Server with RTX PRO 6000 Blackwell Server | 3XS EGX Server with L40S / RTX 6000 Ada | 3XS MGX Server with RTX PRO 6000 Blackwell Server | 3XS MGX Server with H200 NVL | 3XS HGX Server with H200 | 3XS HGX Server with B200 | 3XS HGX Server with B300 | NVIDIA DGX H200 | NVIDIA DGX B200 | NVIDIA DGX B300 | NVIDIA DGX GB200 NVL72 cluster | NVIDIA DGX GB300 NVL73 cluster |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AI performance per GPU (FP4) | 4 PFLOPS | 1.4 PFLOPS* | 4 PFLOPS | 3.3 PFLOPS | 3.9 PFLOPS* | 18 PFLOPS | 18 PFLOPS | 3.9 PFLOPS* | 18 PFLOPS | 18 PFLOPS | 20 PFLOPS | 20 PFLOPS |
| Memory per GPU | 96GB | 48GB | 96GB | 141GB | 141GB | 180GB | 288GB | 141GB | 180GB | 288GB | 372GB | 583GB |
| GPU(s) | Up to 8 | Up to 8 | Up to 8 | Up to 8 | 4 or 8 | 4 or 8 | 4 or 8 | 8 | 8 | 8 | 72 | 72 |
| Max AI performance (FP4) | Up to 32 PFLOPS | Up to 11.2 PLOPS* | Up to 32 PFLOPS | Up to 26.4 PFLOPS | Up to 31.2 PFLOPS* | 144 PFLOPS | 144 PFLOPS | Up to 31.2 PFLOPS* | 144 PFLOPS | 144 PFLOPS | 1,400 PFLOPS | 1,400 PFLOPS |
| Max GPU Memory | 768GB | 384GB | 768GB | 1.1TB | 1.1TB | 1.44TB | 2.3TB | 1.1TB | 1.44TB | 2.3TB | 13.4TB | 21TB |
| Maximum AI model size (FP4)** | 1.2 trillion | 0.6 trillion | 1.2 trillion | 1.7 trillion | 1.7 trillion | 2.2 trillion | 3.6 trillion | 1.7 trillion | 2.4 trillion | 3.6 trillion | 48 trillion | 65 trillion |
| Cost | ££ | £ | ££ | £££ | ££££ | £££££ | ££££££ | ££££ | £££££ | ££££££ | £££££££££ | ££££££££££ |
*Performance is FP8 as Ada Lovelace / Hopper GPUs do not support FP4 **Not necessarily representing a single model - may be multiple large models at cluster scale
Scaling Up
When it comes to scaling 3XS RTX PRO Servers, multiple servers can be connected into a POD architecture configured with shared AI-optimised PEAK:AIO software-defined storage and NVIDIA networking - either Ethernet or InfiniBand.
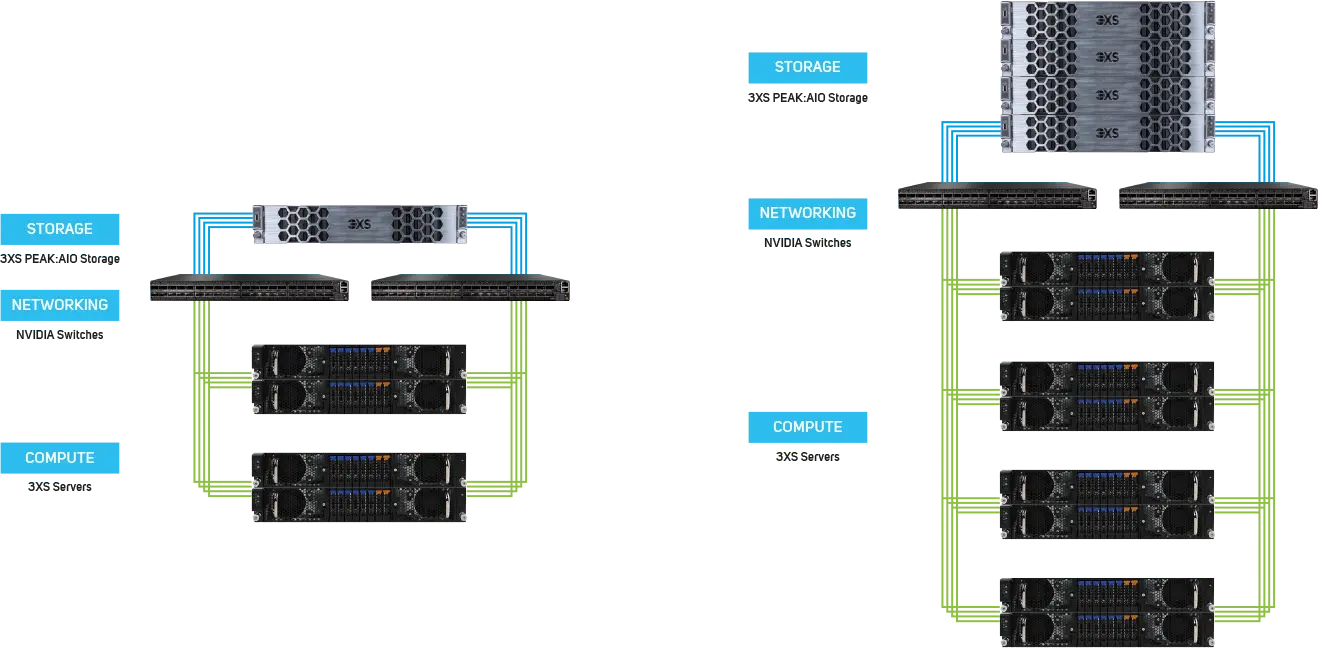
To aid management of the GPUs, NVIDIA Run:ai software enables intelligent resource management and consumption so that users can easily access GPU fractions, multiple GPUs or clusters of servers for workloads of every size and stage of the AI lifecycle. This ensures that all available compute can be utilised and GPUs never have to sit idle. Run:ai's scheduler is a simple plug-in for Kubernetes clusters and adds high-performance orchestration to your containerised AI workloads.

As an NVIDIA Elite Partner, our expert AI team can help you design and deploy 3XS RTX PRO Servers at scale either on-premise or with our range of datacentre hosting partners.
Conclusion
The 3XS RTX PRO Servers are the most cost-effective platform to train AI models providing 768GB of VRAM in a single chassis, with MIG support too if it is intended to be a shared resource. RTX PRO Servers are also ideal for running visualisation workloads too. The scaling options make this a cost-effective platform to scale too, although software like NVIDIA Run:ai would be recommended to get the most from the combined GPUs. For more demanding projects you should consider an or systems thanks to their superior performance and scalability.
Ready to buy?
Click the link below to view the range of AI training solutions. If you still have questions on how to select the perfect system, don't hesitate to contact one of our friendly advisors on 01204 474210 or at [email protected].
CONFIGURE 3XS RTX PRO SERVERS








Proof of Concept
Any of these solutions can be trialed free-of-charge in our proof-of-concept hosted environment. Your trial will involve secure access where you can use a sample of your own data for most realistic insights, and you’ll be guided by our expert data scientists to ensure you get the most from your PoC.
To arrange your PoC, contact our AI team.
Get Cloud Computing in 3 Simple Steps
 1. Choose your GPU
1. Choose your GPU
Browse our available options or connect with a specialist to discuss a bespoke solution.
 2. Rapid Provisioning
2. Rapid Provisioning
We’ll provision your environment and take you through a guided onboarding process.
 3. Enjoy SCAN Cloud
3. Enjoy SCAN Cloud
You’re online! Set up, get to work, and access support anytime.
AI Training in the Cloud
All the AI training servers and appliances covered in this guide can also be provisioned on our Scan Cloud platform. Our cloud server solutions can be configured with a wide variety of NVIDIA GPUs or an entire DGX appliance can be selected.
Simple, Flexible Pricing with No Hidden Fees
No long-term commitments, no extra charges for storage or networking—experience the full benefits of the cloud without the drawbacks.
Reference Architecture for Unrivaled Performance
Harness the power of the latest GPUs for desktops or high-performance GPU clusters, from single GPUs to 8-way systems.
Networking and Storage Built for Performance
All GPU instances include NVMe storage and uncontended network ports, ensuring top-tier performance and data privacy.
Build It Your Way
Custom builds are SCAN’s specialty—every aspect of our Infrastructure-as-a-Service (IaaS) solutions is fully customizable, with UK-based solutions ensuring data sovereignty.
Browse the available Scan Cloud options on or contact our Cloud team.