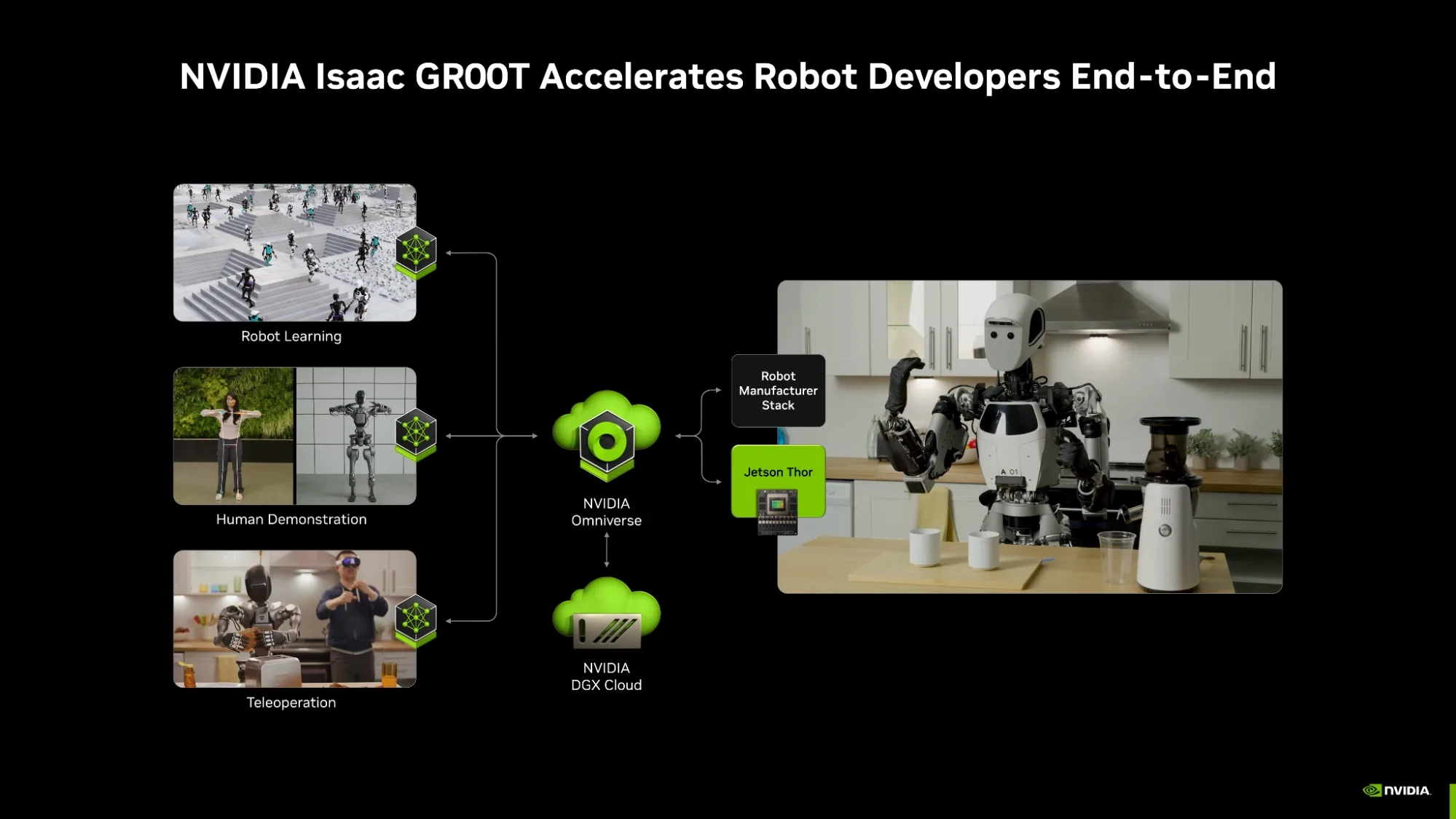
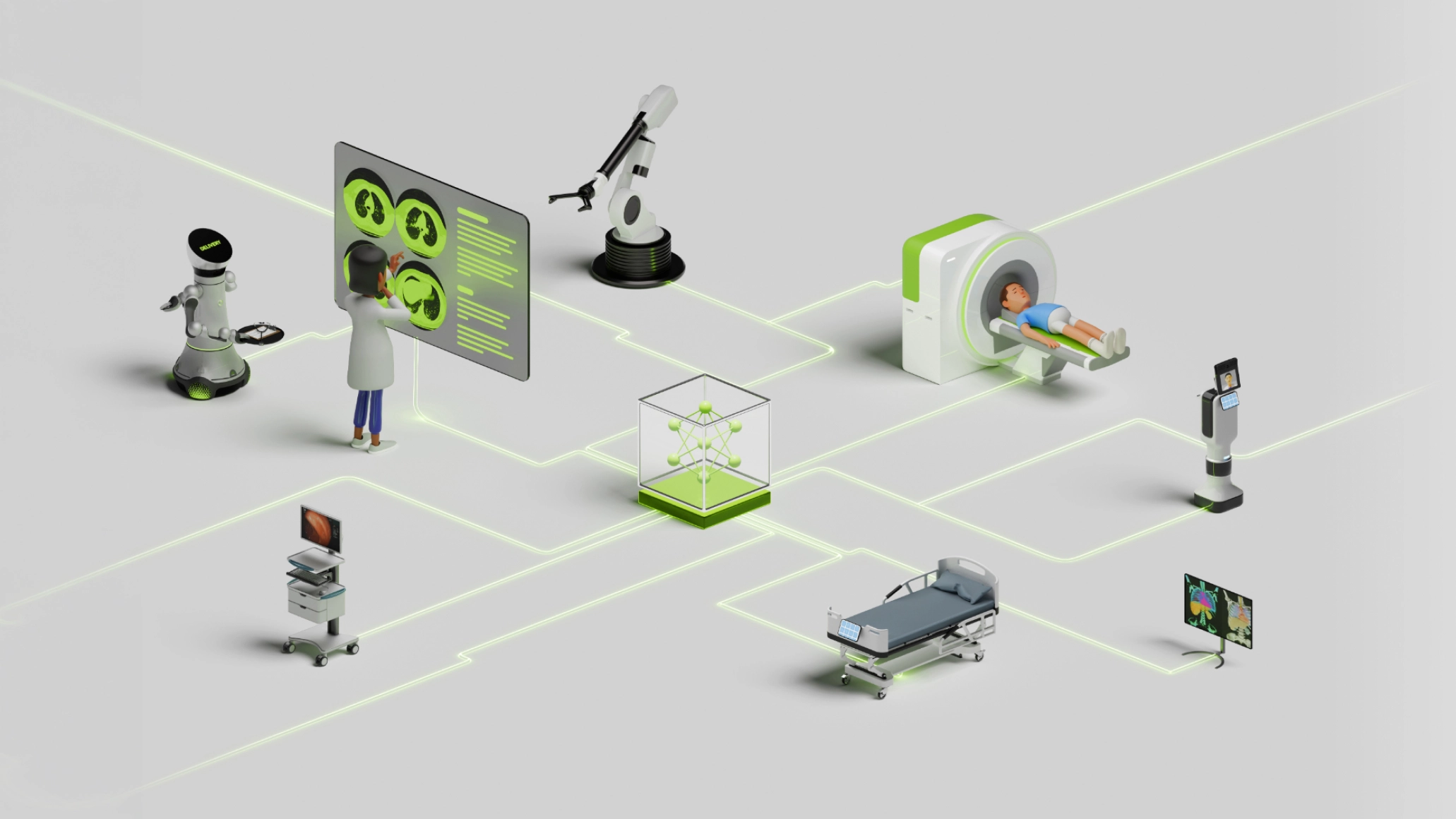
NVIDIA Jetson Thor
NVIDIA Jetson Thor is available as either an AGX developer kit or a choice of two GPU modules - the T5000 and the T4000 which need system integration. With Thor, robots no longer need to be reprogrammed for each new job, as it is the ultimate platform for physical AI, providing powerful compute for generative reasoning and multimodal, multi-sensor processing. Thor can be integrated into next-generation robots to accelerate foundation models, allowing flexibility for challenges such as object manipulation, navigation and following complex instructions.
Architecture
Jetson Thor is a SoC (System on Chip), comprising a Blackwell GPU with 5th gen Tensor cores and an Arm CPU, each sharing a unified memory pool. The AGX Thor Developer Kit and T5000 module have the same specs, with the T4000 module consuming less power at the cost of lower performance. However, the power consumption of all three variants can be configured to meet your project requirements.
| AI Performance (FP4) |
2,070 TOPS |
1,200 TOPS |
| GPU |
NVIDIA Blackwell, 2,560 CUDA cores, 96 5th gen Tensor cores |
NVIDIA Blackwell, 1,536 CUDA cores, 64 5th gen Tensor cores |
| GPU Max Frequency |
1.57GHz |
| CPU |
14-core Arm Neoverse-V3AE |
12-core Arm Neoverse-V3AE |
| Memory |
128GB LPDDR5X |
64GB LPDDR5X |
| Networking |
4x 25GbE |
3x 25GbE |
With its Multi-Instance GPU (MIG) technology and suite of accelerators, Thor can handle real-time video data streaming and AI inference, making it ideal for building AI agents performing video search and summarisation (VSS) tasks at the edge. Thor modules also support a wide range of generative AI models - including VLA (Vision Language Action), LLMs (Large Language Models) and VLMs (Vision-Language Models), delivering seamless cloud-to-edge integration.
Relative Performance & Capability
Jetson Thor is the most powerful inferencing module. It delivers over 7.5x higher AI compute than Jetson Orin, with 3.5x better energy efficiency.
| AI performance (FP4) |
2,070 TOPS |
1,200 TOPS |
275 TOPS |
248 TOPS |
200 TOPS |
157 TOPS |
117 TOPS |
67 TOPS |
34 TOPS |
| Memory |
128GB |
64GB |
64GB |
64GB |
32GB |
16GB |
8GB |
8GB |
4GB |
| Power |
40-130W |
40-70W |
15-60W |
15-75W |
15-40W |
10-40W |
10-40W |
7-25W |
7-25W |
| Dimensions |
243x112mm |
100x87mm |
100x87mm |
100x87mm |
100x87mm |
69.6x45mm |
69.6x45mm |
69.6x45mm |
69.6x45mm |