




PNY NVIDIA A30 24GB Passive Ampere Graphics Card
PNY NVIDIA A30 24GB HBM2 with ECC Passive Graphics Card, 3804 CUDA, 5.2 TFLOPS DP, 10.3 TFLOPS SP, 165 TFLOPS HP
Email me when the availability or price changes
PNY NVIDIA A30 Tensor Core GPU with Ampere Architecture

AI Inference and Mainstream Compute for Every Enterprise NVIDIA A30 Tensor Core GPU is the most versatile mainstream compute GPU for AI inference and mainstream enterprise workloads. Powered by NVIDIA Ampere architecture Tensor Core technology, it supports a broad range of math precisions, providing a single accelerator to speed up every workload. Built for AI inference at scale, the same compute resource can rapidly re-train AI models with TF32, as well as accelerate high-performance computing (HPC) applications using FP64 Tensor Cores. Multi-Instance GPU (MIG) and FP64 Tensor Cores combine with fast 933 gigabytes per second (GB/s) of memory bandwidth in a low 165W power envelope, all running on a PCIe card optimal for mainstream servers.
24GBHBM2 GPU Memory
PCI Express 4.0 x16System interface
3,804CUDA Cores
933 GB/sMemory Bandwidth
Groundbreaking Innovative Technology

NVIDIA AMPERE ARCHITECTUREWhether using MIG to partition an A30 GPU into smaller instances, or NVLink to connect multiple GPUs to accelerate large-scale workloads, A30 can readily handle different-sized acceleration needs, from the smallest job to the biggest multi-node workload. A30's versatility means IT managers can maximize the utility of every GPU in their data center around the clock.

THIRD-GENERATION TENSOR CORESNVIDIA A30 delivers 165 teraFLOPS (TFLOPS) of TF32 deep learning performance. That’s 20X more AI training throughput and over 5X more inference performance compared to NVIDIA T4 Tensor Core GPU. For HPC, A30 delivers 10.3 TFLOPS of performance, nearly 30 percent more than NVIDIA V100 Tensor Core GPU.

NEXT-GENERATION NVLINKNVIDIA NVLink in A30 delivers 2X higher throughput compared to the previous generation. Two A30 PCIe GPUs can be connected via an NVLink Bridge to deliver 330 TFLOPS of deep learning performance.

MULTI-INSTANCE GPU (MIG)An A30 GPU can be partitioned into as many as four GPU instances, fully isolated at the hardware level with their own high-bandwidth memory, cache, and compute cores. MIG gives developers access to breakthrough acceleration for all their applications. IT administrators can offer right-sized GPU acceleration for every job, optimizing utilization and expanding access to every user and application.

HBM2With 24 gigabytes (GB) of high-bandwidth memory (HBM2), with a bandwidth of 933 gigabytes per second (GB/s), researchers can rapidly solve double-precision calculations. HPC applications can also leverage TF32 to achieve higher throughput for single-precision, dense matrix-multiply operations.
STRUCTURAL SPARSITYAI networks have millions to billions of parameters. Not all of these parameters are needed for accurate predictions, and some can be converted to zeros, making the models “sparse” without compromising accuracy. Tensor Cores in A30 can provide up to 2X higher performance for sparse models. While the sparsity feature more readily benefits AI inference, it can also improve the performance of model training.
How Fast is the A30?
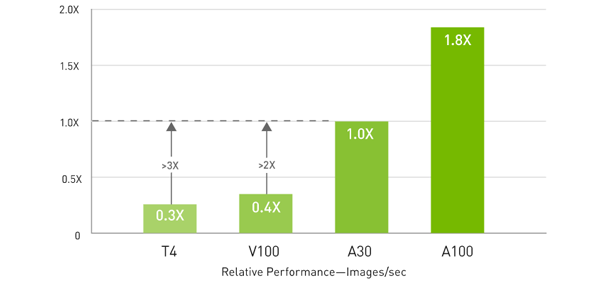
Up to 1.1X higher throughput than V100 and 8X higher than T4 NVIDIA A30 features FP64 NVIDIA Ampere architecture Tensor Cores that deliver the biggest leap in HPC performance since the introduction of GPUs. Combined with 24 gigabytes (GB) of GPU memory with a bandwidth of 933 gigabytes per second (GB/s), researchers can rapidly solve double-precision calculations. HPC applications can also leverage TF32 to achieve higher throughput for single-precision, dense matrix-multiply operations.
High-Performance Data Analytics
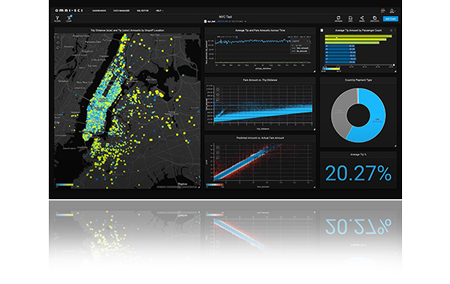
analyze, visualize, and turn massive datasets into insights Accelerated servers with A30 provide the needed compute power – along with large HBM2 memory, 933GB/sec of memory bandwidth, and scalability with NVLink – to tackle these workloads. Combined with NVIDIA InfiniBand, NVIDIA Magnum IO and the RAPIDS™ suite of open-source libraries, including the RAPIDS Accelerator for Apache Spark, the NVIDIA data center platform accelerates these huge workloads at unprecedented levels of performance and efficiency.
| Product Specifications | CUDA Cores | 3804 |
|---|---|---|
| NVIDIA RT Cores | 72 | |
| GPU Memory Size | 24 GB GDDR6 with ECC | |
| Memory Bus Width | 3072-bit | |
| Memory Bandwidth | 933 GB/s | |
| Peak Double Performance | 5.2 TFLOPS (GPU Boost Clocks) | |
| Peak Single Performance | 10,3 TFLOPS (GPU Boost Clocks) | |
| Peak Half Precision | 165 TFLOPS (GPU Boost Clocks) | |
| System Interface | PCI Express 4.0 x16 | |
| Max Power Consumption | 165 W | |
| Power Connectors | 1x 8-pin CPU Power Connector | |
| Weight (w/o extender) | 1024g | |
| Thermal Solution | Passive Heatsink | |
| Form Factor | 111,15 mm (H) x 267,7 mm (L) Dual Slot, Full Height | |
| Warranty | 3 Years | |
