










PNY NVIDIA A100 40GB Passive Ampere Graphics Card
40GB PNY NVIDIA A100, Ampere, 6912 Cores, 432 Tensor, HBM2 w/ ECC, PCIe 4.0 (x16)
Email me when the availability or price changes
- 48HR REPLACEMENT If you need to return this item, your replacement will be dispatched within 2 working days of your product arriving back at Scan.
Suggested Alternatives



PNY NVIDIA A100 Tensor Core GPU with Ampere Architecture

Unprecedented Acceleration at Every Scale PNY NVIDIA A100 Tensor Core GPU provides users with supreme acceleration and power. The NVIDIA A100 Tensor Core GPU delivers unprecedented acceleration at every scale for AI, data analytics, and HPC to tackle the world’s toughest computing challenges. As the engine of the NVIDIA data center platform, A100 can efficiently scale up to thousands of GPUs or, using new Multi-Instance GPU (MIG) technology, can be partitioned into seven isolated GPU instances to accelerate workloads of all sizes. A100’s third-generation Tensor Core technology now accelerates more levels of precision for diverse workloads, speeding time to insight as well as time to market. The NVIDIA Ampere architecture, designed for the age of elastic computing, delivers the next giant leap by providing unmatched acceleration at every scale, enabling these innovators to do their life’s work.
40GBHBM2 GPU Memory
PCI Express 4.0 x16System interface
6,912CUDA Cores
1.6 TB/secMemory Bandwidth
Groundbreaking Innovative Technology

NVIDIA AMPERE ARCHITECTUREA100 accelerates workloads big and small. Whether using MIG to partition an A100 GPU into smaller instances, or NVLink to connect multiple GPUs to accelerate large-scale workloads, A100 can readily handle different-sized acceleration needs, from the smallest job to the biggest multi-node workload. A100’s versatility means IT managers can maximize the utility of every GPU in their data center around the clock.

THIRD-GENERATION TENSOR CORESA100 delivers 312 teraFLOPS (TFLOPS) of deep learning performance. That’s 20X Tensor FLOPS for deep learning training and 20X Tensor TOPS for deep learning inference compared to NVIDIA Volta™ GPUs.

NEXT-GENERATION NVLINKNVIDIA NVLink in A100 delivers 2X higher throughput compared to the previous generation. When combined with NVIDIA NVSwitch™, up to 16 A100 GPUs can be interconnected at up to 600 gigabytes per second (GB/sec) to unleash the highest application performance possible on a single server. NVLink is available in A100 SXM GPUs via HGX A100 server boards and in PCIe GPUs via an NVLink Bridge for up to 2 GPUs.

MULTI-INSTANCE GPU (MIG)An A100 GPU can be partitioned into as many as seven GPU instances, fully isolated at the hardware level with their own high-bandwidth memory, cache, and compute cores. MIG gives developers access to breakthrough acceleration for all their applications, and IT administrators can offer right-sized GPU acceleration for every job, optimizing utilization and expanding access to every user and application.

HBM2With 40 gigabytes (GB) of high-bandwidth memory (HBM2), A100 delivers improved raw bandwidth of 1.6TB/sec, as well as higher dynamic random-access memory (DRAM) utilization efficiency at 95 percent. A100 delivers 1.7X higher memory bandwidth over the previous generation.
STRUCTURAL SPARSITYAI networks are big, having millions to billions of parameters. Not all of these parameters are needed for accurate predictions, and some can be converted to zeros to make the models “sparse” without compromising accuracy. Tensor Cores in A100 can provide up to 2X higher performance for sparse models. While the sparsity feature more readily benefits AI inference, it can also improve the performance of model training.
How Fast is the A100?
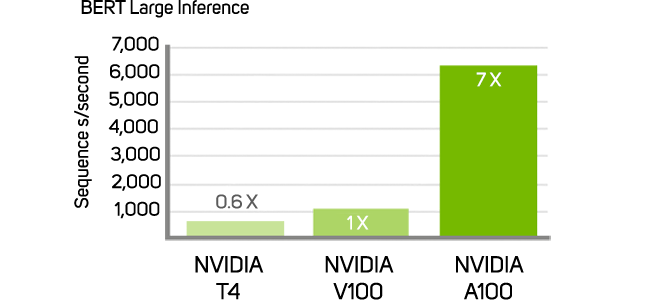
up to 7x higher performance with multi instance gpu for AI Inference The NVIDIA A100 Tensor Core GPU is the flagship product of the NVIDIA data center platform for deep learning, HPC, and data analytics. The platform accelerates over 700 HPC applications and every major deep learning framework. It’s available everywhere, from desktops to servers to cloud services, delivering both dramatic performance gains and cost-saving opportunities.



