PRESSZONE
UNLOCK THE POWER OF LLMS WITHOUT VRAM LIMITATIONS
One of the biggest challenges with running LLMs locally isn't GPU performance, it's the sheer amount of VRAM required to train them. So what happens if you cannot afford to upgrade the hardware configuration of your workstations and servers?
There are a few solutions to this, the most common of which is quantisation, a mathematical process of converting data into a simpler and smaller format that takes up less VRAM. However, quantisation inevitably makes the output from the LLM less accurate, so isn't ideal for all use cases.
However, there is now another solution to the VRAM requirements of LLMs – offloading. This involves splitting up the LLM, so it runs partially in VRAM and in another source of memory in the system. And voila, you can now run complex LLMs in systems with limited VRAM.
Scan has partnered with MiPhi to bring its aiDAPTIV+ offloading solution to the UK. This takes the form of two products, high-endurance aiDAPTIVCache SSDs that act as VRAM extenders, plus aiDAPTIV middleware that sits between the AI framework and hardware.

In principle, this works the same way as virtual memory in Windows, cost-efficiently expanding the memory capacity of a system. In the case of MiPhi, unlocking large model training without having to buy new GPUs or systems, providing you the ability to run models previously only possible on datacentre-grade hardware.
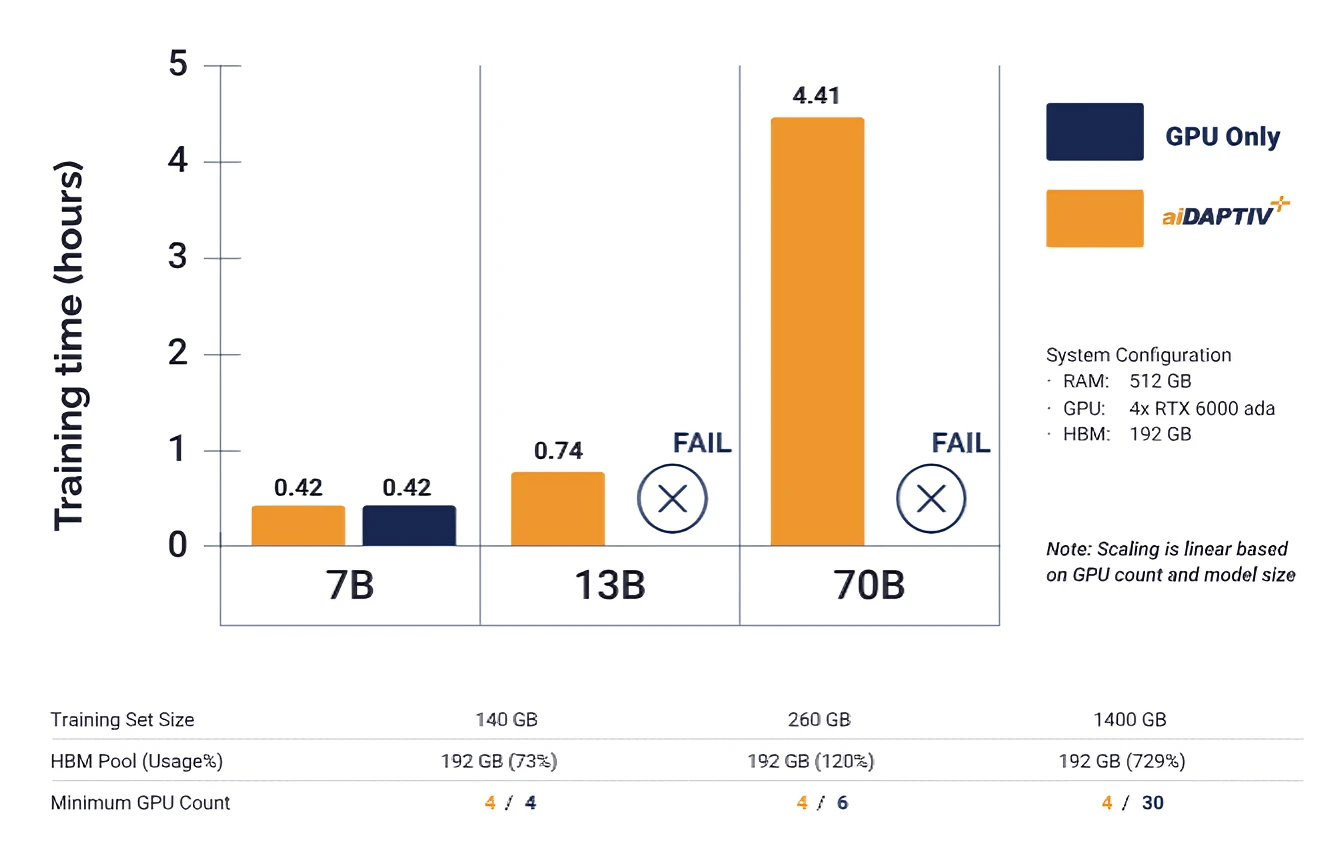
For instance, adding aiDAPTIV+ with 2x 2TB drives to a system with four NVIDIA RTX 6000 Ada GPUs unlocked the ability to run models with up to 10x more parameters than when purely run in VRAM.
Configuring an offloading solution such as aiDAPTIV+ can be complex, so we're offering a free trial on Scan Cloud, you can even use your own data to validate the experience. Sign up today to unlock the power of LLMs without having to invest in new GPUs.