Professional AI Infrastructure Management and Orchestration Solutions - NVIDIA Mission Control, Run:AI, and SLURM Workload Management Services
AI Management & Orchestration
Power is nothing without Control. Software solutions to monitor, manage, orchestrate, and optimise AI workloads.
AI Workload Management
As AI workloads move from development and training into inferenced solutions, their availability and integration to the wider business becomes as important as any other business-critical application.
Platforms running AI and HPC workloads require software suites that can effectively monitor and utilise the whole environment for management.
The most expensive GPU to any organisation is an idle GPU. SCAN provide both self-managed and fully managed services for AI platform management and orchestration - take a trial of NVIDIA software on SCAN Cloud to see for yourself.

NVIDIA Mission Control
Designed to manage AI Factories, NVIDIA Mission Control provides a full suite of tools that integrate with NVIDIA hardware appliances. It powers the latest NVIDIA GPUs across data centers, bringing intelligent monitoring capabilities to divert workloads away from any unavailable GPUs due to incident or maintenance, workload orchestration to control jobs and resources allocated to users, and full management of the platform so that every aspect, from management dashboards through to energy utilisation can be customised based on platform load and project requirements.

NVIDIA Run:AI for Orchestration
NVIDIA Run:ai accelerates AI and machine learning operations by addressing key infrastructure challenges through dynamic resource allocation, comprehensive AI life-cycle support, and strategic resource management. By pooling resources across environments and utilizing advanced orchestration, NVIDIA Run:ai significantly enhances GPU efficiency and workload capacity. With support for public clouds, private clouds, hybrid environments, or on-premises data centers, NVIDIA Run:ai provides unparalleled flexibility and adaptability.
Learn More >
SLURM Workload Management
Slurm is an open source, fault-tolerant, and highly scalable cluster management and job scheduling system for large and small Linux clusters.
Many large HPC organisations use SLURM at scale for its ability to allocate jobs across the platform, as a framework for controlling parallelised workloads across HPC clusters, and its functionality to manage contention by maintaining a job queue.
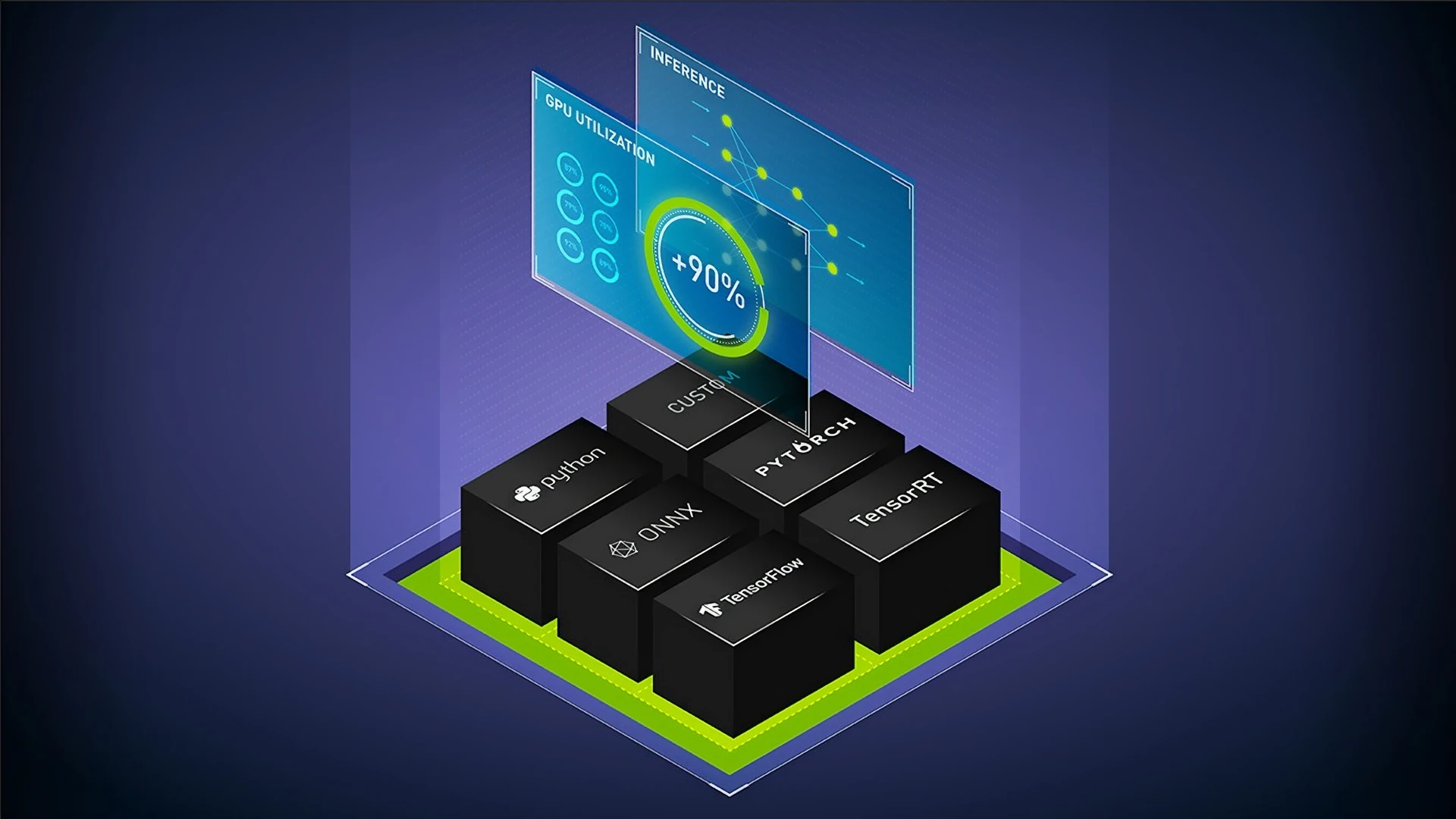
Customisable Management Services
Whether it’s a traditional HPC platform, an AI Factory or an AI Cloud, SCAN can provide full management services across multiple platforms that can be tailored to complement an existing technical team.
As an Elite NVIDIA Partner and certified NVIDIA Managed Service Provider, we’re here to help bring in the experience and expertise as and when it’s needed.
A Safe Pair of Hands
Partnering with SCAN to provide ongoing management services for you AI platform means choosing a trusted advisor in the field. SCAN are the UK’s leader in AI solutions, from starting up to scaling up.
Our certified engineers and specialists meticulously design AI solutions tailored specifically to your vision for utilising compute, from training large scale LLMs to running vast and complex CFD simulations. Our aim is to be a technology partner that removes any concerns around infrastructure management and job orchestration, allowing our customers to focus on how best to accelerate their applications and workloads to make innovative breakthroughs that will make step-changes to the world we live in.
