A100 introduces double-precision Tensor Cores, providing the biggest milestone since the introduction of double-precision computing in GPUs for HPC. This enables researchers to reduce a 10-hour, double-precision simulation running on NVIDIA V100 Tensor Core GPUs to just four hours on A100. HPC applications can also leverage TF32 precision in A100’s Tensor Cores to achieve up to 10X higher throughput for single-precision dense matrix multiply operations.
5 Innovations Driving Performance
The NVIDIA Ampere architecture, designed for the age of elastic computing, delivers the next giant leap by providing unmatched acceleration at every scale The A100 GPU brings massive amounts of compute to datacentres. To keep those compute engines fully utilised, it has a leading class 1.6TB/sec of memory bandwidth, a 67 per cent increase over the previous generation DGX. In addition, the DGX A100 has significantly more on-chip memory, including a 40MB Level 2 cache—7x larger than the previous generation—to maximise compute performance.
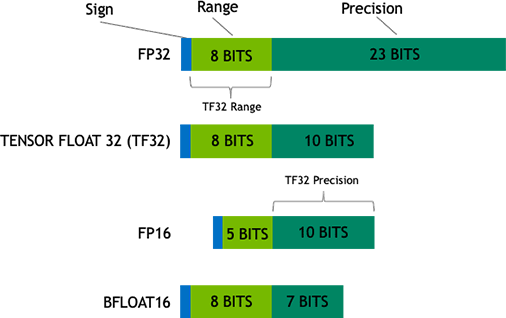
TF32 running on Tensor Cores in A100 GPUs can provide up to 10x speedups compared to single-precision floating-point math (FP32) on Volta GPUs. Combining TF32 with structured sparsity on the A100 enables performance gains over Volta of up to 20x. Applications using NVIDIA libraries enable users to harness the benefits of TF32 with no code change required. TF32 Tensor Cores operate on FP32 inputs and produce results in FP32. Non-matrix operations continue to use FP32.
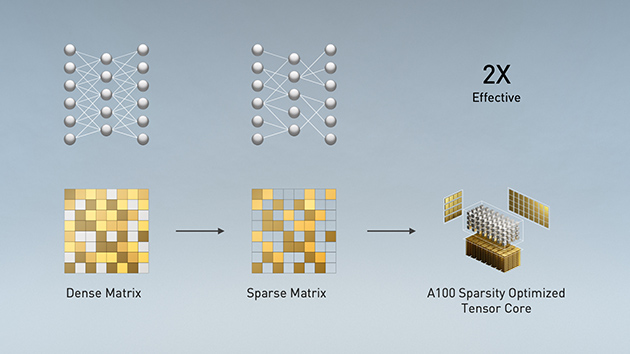
Modern AI networks are big and getting bigger, with millions and in some cases billions of parameters. Not all of these parameters are needed for accurate predictions and inference, and some can be converted to zeros to make the models 'sparse’ without compromising accuracy. Tensor Cores in A100 can provide up to 2x higher performance for sparse models. While the sparsity feature more readily benefits AI inference, it can also be used to improve the performance of model training.
Multi-Instance GPU (MIG) expands the performance and value of each NVIDIA A100 GPU. MIG can partition the A100 GPU into as many as seven instances, each fully isolated with their own high-bandwidth memory, cache, and compute cores. Now administrators can support every workload, from the smallest to the largest, offering a right-sized GPU with guaranteed quality of service (QoS) for every job, optimising utilisation and extending the reach of accelerated computing resources to every user.
Expand GPU access to more users
With MIG, you can achieve up to 7X more GPU resources on a single A100 GPU. MIG gives researchers and developers more resources and flexibility than ever before.
Optimise GPU utilisation
MIG provides the flexibility to choose many different instance sizes, which allows provisioning of right-sized GPU instance for each workload, ultimately delivering optimal utilization and maximizing data center investment.
Run simultaneous mixed workloads
MIG enables inference, training, and high-performance computing (HPC) workloads to run at the same time on a single GPU with deterministic latency and throughput.
Simultaneous workload execution with guaranteed quality of service
All MIG instances run in parallel with predicatable throughput & latency
Right-sized GPU allocation
Different sized MIG instances based on target workloads
Flexibility
To run any type of workload on a MIG instance
Diverse deployment environment
Supported with Bare metal, Docker, Kubernetes, Virtualised env.
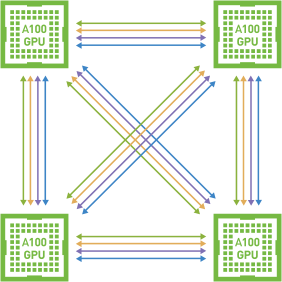
Scaling applications across multiple GPUs requires extremely fast movement of data. The third generation of NVIDIA NVLink in A100 doubles the GPU-to-GPU direct bandwidth to 600GB/s, almost 20x more than PCI-E 4.0. When paired with the latest generation of NVIDIA NVSwitch, all GPUs in the server can communicate with each other at full NVLink speed for incredibly fast training.
NVLink and NVSwitch are essential building blocks of the complete NVIDIA datacentre solution that incorporates hardware, networking, software, libraries, and optimised AI models and applications from NVIDIA GPU Cloud (NGC).
Flexible Configurations
In addition to the NVIDIA DGX A100 universal system for AI infrastructure we also have developed a range of training systems powered by the NVIDIA A100 GPU. These systems are customisable to your requirements and are available in variety of configurations in both the high density SXM4 and industry standard PCI-E form factors.
SXM4 Servers
4 GPUs
8 GPUs
Supermicro 2124GQ-NART
4x NVIDIA A100 GPUs with NVLink
2x AMD EPYC 7002 CPUs
Up to 8TB of DDR4 3200 ECC Registered
4x 2.5in HDDs/SSDs
Up to 4x Mellanox NICs
Redundant 2200W PSUs
2U 19in rack server
8x NVIDIA A100 GPUs with NVLink and NVSwitch
2x AMD EPYC 7002 CPU
Up to 8TB of DDR4 3200 ECC Registered
6x 2.5in HDDs/SSDs
Up to 2x Mellanox NICs
Redundant 2200W PSUs
4U 19in rack server
4x NVIDIA A100 GPUs with NVLink
AMD EPYC 7002 CPU
Up to 2TB of DDR4 3200 ECC Registered
1x M.2 SSD, 8x 3.5in HDDs/SSDs
Up to 2x Mellanox NICs
Redundant 1600W PSUs
2U 19in rack server
8x NVIDIA A100 GPUs with NVLink
AMD EPYC 7002 CPU
Up to 8TB of DDR4 3200 ECC Registered
24x 2.5in HDDs/SSDs
Up to 2x Mellanox NICs
Redundant 2000W PSUs
5U 19in rack server