

Get in touch with our AI team.
Beginner’s Guide to Deep Learning and AI

It seems machine learning (ML) and artificial intelligence (AI) are being mentioned everywhere you turn these days, and it’s true that the number of systems and software solutions aimed at these workloads has exploded over the last few years. But what exactly do we mean by ML and AI and what should we make of other increasingly used terms such as deep learning (DL), large language models (LLMs) and generative AI?
This guides walks you through the principles, terminology and processes of machine learning, deep learning and AI to help provide a clearer understanding of these technologies, how they work, what drives them and how businesses and organisations can take advantage. Alternatively, we also created a six-part video series to accompany this guide - simply click on the video to start episode one.
Deep Learning or AI?
AI (Artificial Intelligence) is the umbrella term for the designing of systems to mimic human intelligence. It is broken down into subsets including machine learning and deep learning. With machine learning, the goal is to create a simulation of human learning so that an application can adapt to uncertain or unexpected conditions. To perform this task, machine learning relies on algorithms to analyse huge datasets and perform predictive analytics far faster than any human can. Machine Learning uses various techniques including statistical analysis, finding analogies in data, using logic, and identifying symbols. In contrast, deep learning processes data using computing units, called neurones, arranged into ordered sections, called layers. This technique, at the foundation of deep learning, is called a neural network, and it is intended to mimic how the human brain learns.

Neural networks and deep learning
CNNs & RNNS
Unlike machine learning algorithms, whose performance plateaus with scale and volume of data, larger neural networks with greater quantities of data see their performance continue to increase. This is because the computer uses the many multitude of layers to solve the problem one small step at a time. This is referred to as a Convolutional Neural Network (CNN), where each artificial neurone is connected to a small window over the input or previous layer. For example, in a visual task, each neurone in the first convolution layer will only see a small part of the image, maybe only a few pixels. This convolution layer consists of multiple maps, each searching for a different feature, and each neurone in a map searching for that feature in a slightly different location.
This first layer will come (after some training) to identify useful low level features in the image, such as lines, edges, and gradients in different orientations. This convolution layer is then sub-sampled in what is called a pooling layer, before the whole process starts again with another convolution layer this time finding combinations of the features of the previous layer (lines, corners, curves etc). Once this process has occurred multiple times, fully connected layers look at the complete output of the previous layer and identify the major features together to give a final result or classification.
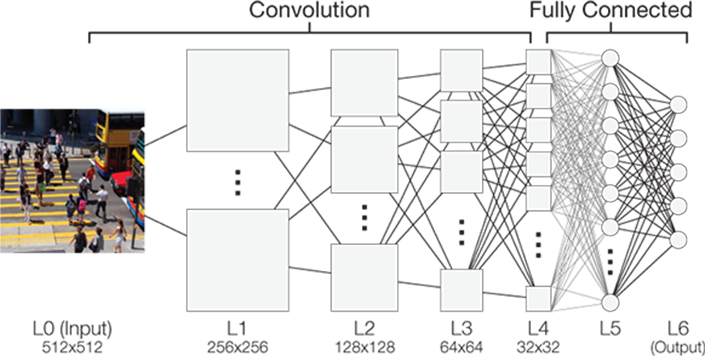
Alternatively a Recurrent Neural Network (RNN) can be employed - this works in the same way as a CNN but adds a built-in feedback loop where the output from one layer is fed back into the layer preceding it. This enables them to have an internal memory where the network is able to remember the input received, facilitating their accuracy in predicting the next event. RNNs are particularly adept at recognising patterns in a sequence of data, such as text, handwriting or spoken words - often grouped as natural language processing (NLP).
LLMs & Generative AI
These can be used to generate automated subtitles or in translation. When NLP reaches a huge scale drawing on vast amounts of data, such as sections of the Internet, the term large language model or LLM is used. LLMs are typically used in auto assistants and chatbots where the aim is to produce a human like response - they also form the basis for generative AI that is capable of generating text, images, or other media using generative models. Generative AI models learn the patterns and structure of their input training data and then generate new data that has similar characteristics.
Powering Deep Learning
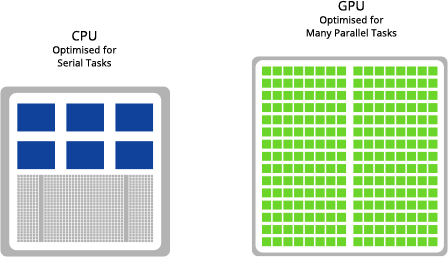
Having understood the principles behind deep learning, it is clear that there are many small tasks occurring at the same time in parallel. This type of parallel computing is very specific and does not suit all types of processor. The CPU (central processing unit) is typically seen as the brain of a computer and it is very adept at doing tasks very quickly and often at the same time. However it does reach a limit as to how much concurrent, or parallel, tasks can be achieved without bottlenecks forming. GPUs (graphics processing unit) are designed for the rendering of high resolution images and video concurrently - both hugely parallel workloads. Because GPUs can perform parallel operations on multiple sets of data, they are also perfect for non-graphical tasks such as machine learning and scientific computation.
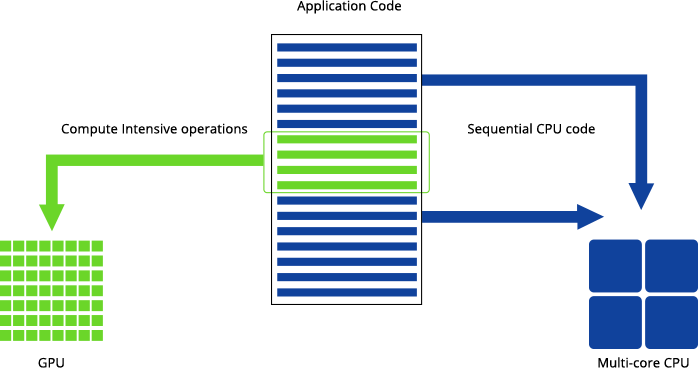
Adding such GPUs to a system is referred to as GPU-accelerated computing, due to the fact that intensive parallel workloads are off-loaded from the CPU and moved to the GPU for better performance. Designed with thousands of cores running simultaneously, GPUs enable massive parallelism where each core is focused on making efficient calculations.
How GPU-acceleration works
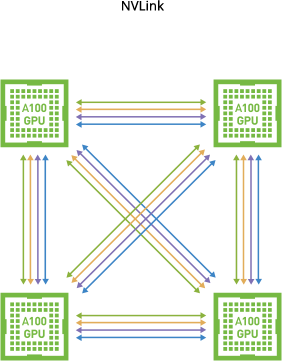
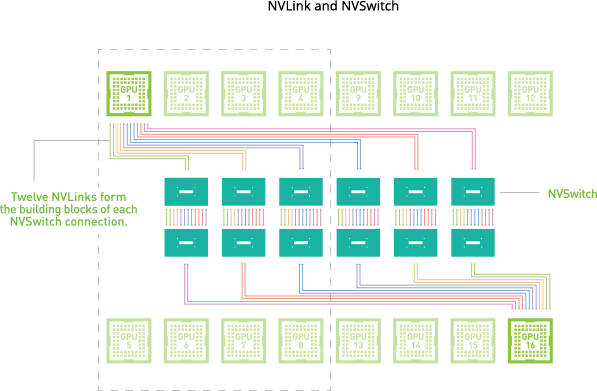
To leverage this multi-core design even more, GPUs are often grouped together to deliver even more parallel processing power, this is done by two technologies called NVLink and NVSwitch - both proprietary NVIDIA interconnects that allows GPU - GPU communication at much faster rates than the PCIe bus can provide, boosting performance in multi-GPU system configurations. In some configurations you can pool the memory of two GPUs together to form a single large unified memory, ideal for working with large datasets.
Depending on budget and performance required NVIDIA produce a wide range of GPUs perfect for scientific research, high performance computing (HPC) and deep learning uses.
Applications, Frameworks, Libraries and Languages
The building blocks of all AI software applications and deep learning frameworks are the underlying programming languages and their libraries. Applications automate as much programming as possible, so you only need to customise and add to the groundwork already in place to deliver your desired outcome. Frameworks & libraries require much more programming knowledge and input, but allow for a more specific and tailored result. Finally using direct programming commands in a given language allow for complete customisation but the skill levels required are substantial. The tabs below give an overview of the popular types of each you may come across.
Applications
NVIDIA AI Enterprise is a subscription service providing a range of tailored applications delivered via the NVIDIA GPU Cloud (NGC). These pre-trained and configured frameworks and libraries accelerate AI research for specific use cases, such as healthcare (Clara), robotics (Isaac), recommendation engines (Merlin) and translation (NeMo) to name just a few.



Data for Deep Learning
We’ve mentioned that deep learning relies on huge datasets (often referred to as Big Data), being fed to the GPUs that then perform the parallel processing in the framework of your choice. However, this data needs to be prepared prior to ingest into the system. Data preparation is the process of readying data for the training, testing, and implementation of an algorithm. It’s a multi-step process that involves data collection, structuring and cleaning, feature engineering, and labelling. These steps play an important role in the overall quality of your deep learning model, as they build on each other to ensure a model performs to expectations.
Once you have collected the data, you would start by preprocessing and cleaning it. This includes organising and formatting, standardising, and dealing with any missing data. While data preprocessing is a way of refining data, feature engineering is the process of creating features to enhance it. Feature engineering allows you to define the most important information in your dataset, and utilise domain expertise to get the most out of it. This might mean breaking data into multiple parts to clarify particular relationships.
Finally data labelling is a key part of data preparation for deep learning because it specifies which parts of the data the model will learn from. Though improvements in unsupervised learning have resulted in deep learning projects that do not require labeled data, many systems still rely on labeled data to learn and perform their given tasks.






As we’ve mentioned to get the most from deep learning the datasets are better the larger they are. However this presents problems as the entire dataset cannot be fed into the system all at once, so batches are used. Batch sizes will usually be defined by the capabilities of your hardware, most importantly the available GPU memory, as you will not want to overload the system. Each time a batch of data is fed into the system this is referred to as an iteration, and when all batches have been though the system once it is referred to as an epoch. It is common that full training of even an average size dataset may require several batches per epoch and many epochs.
There are multiple software packages available that are specifically designed to help with data cleansing, feature engineering,
visualisation, data labelling and more.
The Stages of Deep Learning
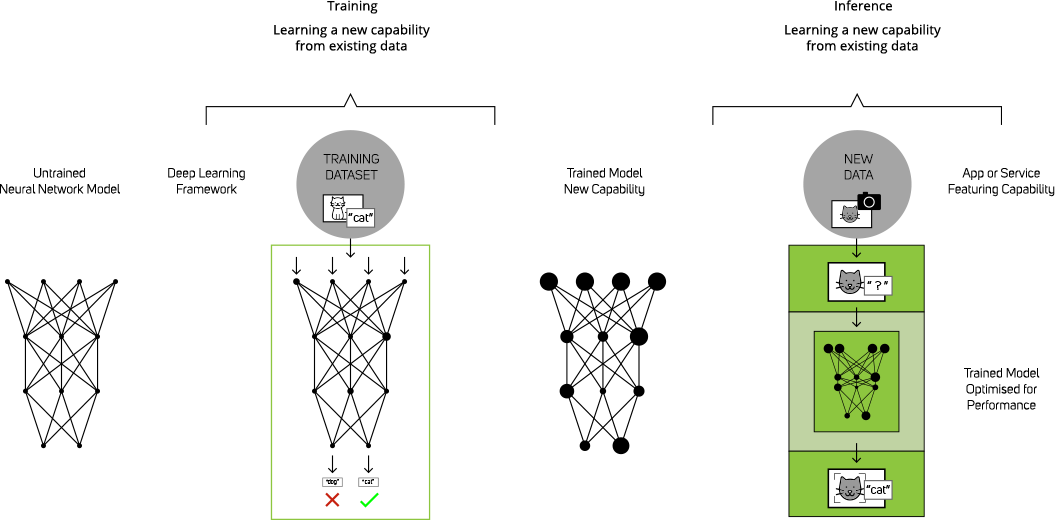
Deep learning can be broken down into three stages - development, training and inferencing. Each of these stages has different hardware requirements and involves different approaches.
Development
Development of an AI model starts out with the data collection and preparation steps outlined above. Once the data is ready is can be subjected to the libraries and frameworks to begin building your CNN and AI model. As this stage is experimental and the CNN will involve only a few layers as it is best to use small datasets so models can be created quickly and scrapped if they aren’t what is required. This stage can be carried out on relatively low powered hardware – typically one or two GPUs is sufficient. However development workstations with four GPUs provide many models to be started at once so time to your ideal version is reduced.
Once you think you’re on the right lines the small model can be scaled up and fully trained, requiring a much greater hardware demand.
Training
When training a neural network, training data is put into the first layer of the network, and individual neurones assign a weighting to the input — how correct or incorrect it is — based on the task being performed. In an image recognition network, the first layer might look for edges. The next might look for how these edges form shapes — rectangles or circles. The third might look for particular features — such as shiny eyes and button noses. Each layer passes the image to the next, until the final layer and the final output determined by the total of all those weightings is produced.
Let’s say the task was to identify images of cats. The neural network gets all these training images, does its weightings and comes to a conclusion of cat or not. What it gets in response from the training algorithm is only “right” or “wrong”. And if the algorithm informs the neural network that it was wrong, it doesn’t get informed what the right answer is. The error is propagated back through the network’s layers and it has to guess at something else. In each attempt it must consider other attributes — in this example attributes of “catness” — and weigh the attributes examined at each layer higher or lower. Then it guesses again. And again. And again. Until it has the correct weightings and gets the correct answer practically every time. It is this repeated process of hundreds or thousands of training epochs that make this stage very compute intensive, and that’s why you’ll usually see systems aimed at AI training being multi-GPU servers to provide as much power as possible, with training systems often having as many as eight GPUs
Inferencing
To make use of all that training in the real world, you need a speedy application that can retain the learning and apply it quickly to data the model has never seen. That is inferencing - taking smaller batches of real-world data and quickly coming back with the same correct answer. This is achieved in two ways - the first approach looks at parts of the neural network that don’t get activated after it’s trained. These sections just aren’t needed and can be pruned away. The second approach looks for ways to fuse multiple layers of the neural network into a single computational step.
It’s akin to the compression that happens to a digital image. Designers might work on these huge, beautiful, million pixel-wide and tall images, but when they go to put it online, they’ll turn into a compressed image or video. It’ll be almost exactly the same, often indistinguishable to the human eye, but at a smaller resolution. Similarly with inferencing you’ll get almost the same accuracy of prediction, but simplified, compressed and optimised for runtime performance. Because of this downsizing inferencing can be carried out by less powerful hardware - often a single GPU system or an endpoint device with an embedded GPU module - ideal for siting out in the real world rather a datacentre.
Deep Learning Performance
We’ve seen how the many processing cores in a GPU are designed to process hugely parallel workloads with the objective of delivering results in ever shorter time frames. However, there are a number of factors that define how quickly you can see results, the primary one being accuracy of the results required - or precision. Precision refers to the number of decimal places, or in computer terms ‘bits’ of any given result - for example 3.14 is less precise than 3.141592654. Having more bits or decimal places to represent each number gives scientists the flexibility to represent a larger range of values, with room for a fluctuating number of digits on either side of the decimal point during the course of a computation - this is called Floating Point (FP).
Within GPU specification sheets you will see terms like FP32, FP64 or FP16. FP32 refers to 32 decimal places and is termed single precision; FP64 - twice as precise at 64 decimal places is called double precision; and FP16 being half as precise is termed half-precision. The higher precision level a machine uses, the more computational resources, data transfer and memory storage it requires. It costs more and it consumes more power. Since not every workload requires high precision, AI researchers can benefit by mixing and matching different levels of precision.
NVIDIA H100
FP64/TF64 67 TFLOPS
FP32/TF32 989 TFLOPS
FP16/TF16 1,979 TFLOPS
FP8/INT8 3,958 TFLOPS

Going back to GPU specifications you’ll often see a performance number written in FLOPS (floating point operations per second) - as above. It will also be caveated with an FP number - for example 312 TeraFLOPS (or TFLOPS) at FP32. This tells you that the GPU is capable of 312 trillion calculations per second delivering single precision results - to 32 decimal places. Some GPUs are designed to excel at a certain precision, however newer GPUs featuring Tensor cores are designed to excel at mixed precision calculations.
Once a model is trained and ready for inference - obtaining results from a new data set - the precision is often lowered still to 8- or even 4-bits or decimal places - this is referred to as INT8 or INT4 - Integer 8 or Integer 4. Once you know a model gives accurate results moving to a lower precision decreases power and GPU memory burden to deliver results faster.
Depending on budget and performance required, NVIDIA produce various ranges of GPUs each aimed at delivering performance at different precision levels, including the new Tensor core models ideal for mixed precision calculations.
Use Cases for Deep Learning
Businesses are increasingly turning to deep learning and AI to solve their greatest challenges. Just a few of the many use cases include enabling more accurate, faster diagnoses in healthcare, offering personalised customer experiences in retail, minimising downtime in manufacturing through predictive maintenance or improving traffic flow by creating smart cities. When powerful GPU-accelerated platforms are integrated into existing workflows, business processes can be improved and industry transformed. Worldwide spending on AI technologies is expected to reach £150 billion in 2023 with human-centric industries, such as financial services, retail and healthcare expected to be the biggest spenders, closely followed by asset-intensive industries including manufacturing, energy and transport.












The latest types of AI applications, including LLMs and generative AI, that we touched on earlier, span all industries as the technology can be applied to many use cases. You can learn more about specific uses cases and success stories in many industry sectors by reading our many and varied case studies.
VIEW CASE STUDIESNext Steps
This guide is intended to introduce the concepts of AI and deep learning, give an overview of how they work and introduce commonly used terms and ideas. If you’ve read this, or watched our video series and are interested in further learning, Scan is an accredited NVIDIA Ideation Workshop and Deep Learning Institute course provider. We regularly run both online and classroom-based courses designed at expanding knowledge with guided learning and hands-on tutorials.

A good place to start is with the Fundamentals of Computer Vision course where you’ll learn how deep learning works through hands-on exercises in computer vision and natural language processing. You will train deep learning models from scratch, learning tools and tricks to achieve highly accurate results. You’ll also learn to leverage freely available, state-of-the-art pre-trained models to save time and get your deep learning application up and running today.
VIEW COURSES