
NVIDIA AI Frameworks and Applications from Scan AI
AI Software
Optimised libraries and frameworks from NVIDIA that accelerate agentic AI model development.
AI Software Ecosystem
Software tools, libraries, SDKs, frameworks and applications are the building blocks of all AI models. Their use helps accelerate the development and deployment of AI agents tailored to a wide variety of use cases.
NVIDIA AI Enterprise is an end-to-end software platform containing everything you need to get started in AI. Optimised for NVIDIA GPU platforms, each collection of libraries, frameworks and NVIDIA Inference Microservices (NIMs) is specifically designed to reduce the complexity of building AI applications from scratch.
NVIDIA Blueprints go one step further providing pre-trained reference AI workflows, customisable with your own business data, for common implementations including Retrieval-Augmented Generation (RAG), Video Search and Summarisation (VSS), digital human avatars, and customer service bots.

Customer Service
AI agents for customer service go beyond conversational AI, scripted workflows, and basic automation to enable AI systems that can reason, plan, and take autonomous action across a wide breadth of customer service operations. The frameworks below contain tools and libraries for developing agent attributes from appearance to speech, conversational skills, translation, recommendations and more.
AI for Media
NVIDIA AI for Media (formerly Maxine) is a collection of SDKs, NIMs and Blueprints that enhance audio, video, and create augmented reality effects for visual workflows, including video conferencing and virtual customer service. It enables studio-quality audio effects such as background noise removal, echo correction, and voice quality enhancement — all using a standard microphone. Similarly, a regular webcam can be used to generate video effects including realtime background removal, relighting, super-resolution, and gaze, face and body tracking.
A further feature adjusts a user's gaze to make it appear they are looking directly at the camera, even while reading from a screen.
Example use cases:
- Telehealth appointments
- Presenting livestreams
- IPTV broadcasting

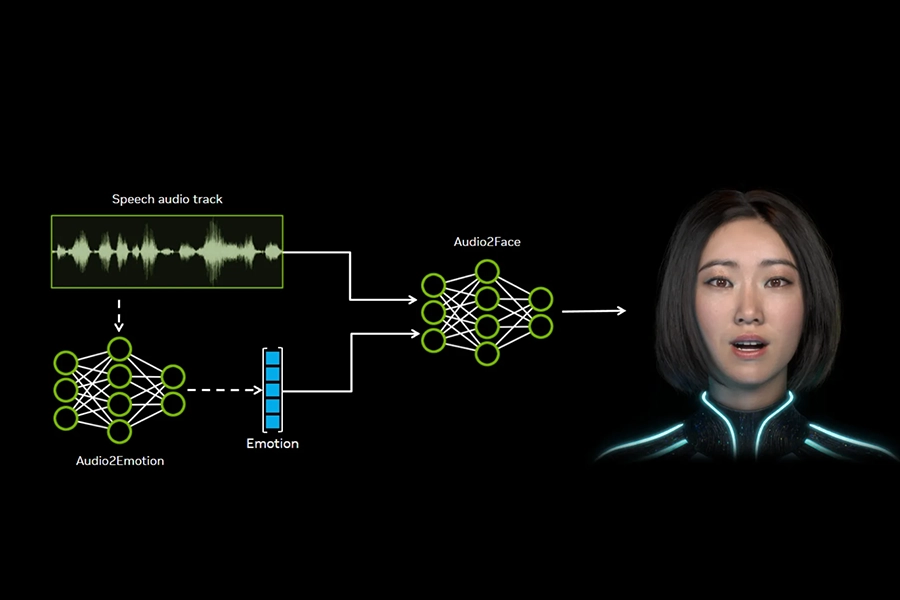
Audio2Face
NVIDIA Audio2Face automatically generates realistic 3D facial animations, lip-syncing, and emotional expressions directly from audio files. It works by analysing acoustic features such as phonemes and intonation to create a stream of animation data, which is then mapped to a character's facial poses. This data can then be rendered offline for pre-scripted content or streamed in real-time for dynamic, AI-driven characters. Furthermore, it works with any language, including songs.
Audio2Face is part of the NVIDIA Avatar Cloud Engine (ACE) platform, along with Riva for speech development; and Nemotron to add reasoning and context for humanlike interaction. Furthermore, Audio2Face can be used with the Omniverse platform, enabling collaborative development and testing.
Example use cases:
- Next-generation interactive avatars for customer service
- Humanoid robots for virtual factories
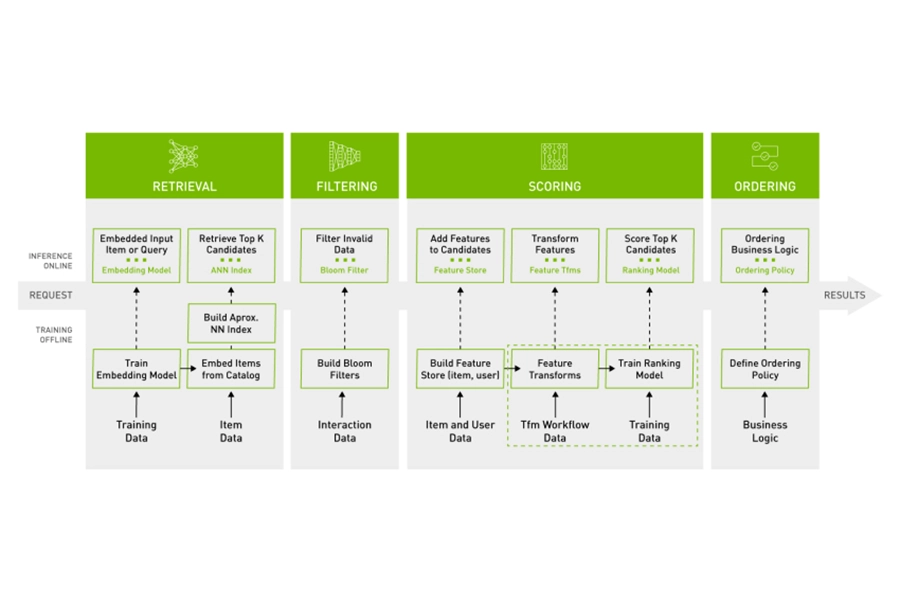
Merlin
NVIDIA Merlin is an open source recommender systems framework, designed to streamline the building of recommenders by addressing common preprocessing, feature engineering, training, and inference challenges. Merlin consists of several specialised libraries designed to handle different stages of the recommendation pipelines — each optimised to support the retrieval, filtering, scoring and ordering of data — all controlled through easy-to-use APIs.
Merlin can pre-process terabyte-scale datasets on GPUs up to 10x faster than CPU-based Apache Spark models, delivering much improved predictions resulting in increased click-through rates.
Example use cases:
- Online shopping decision trees
- Customer service auto-attendants
Nemotron
NVIDIA Nemotron is a family of large language models (LLMs) and small language models (SLMs) that provide digital humans with intelligence — capable of providing contextually aware responses for humanlike conversations. It consists of several streams offering pre-trained models with parameters in the billions (B) — Nano (30B) delivers the highest accuracy and efficiency for targeted tasks; Nano Omni (30B) consolidates video, audio, image, and text understanding for a simplified agent workflow; Super (120B) is designed for addressing complex tasks in multi-agent environments; and Ultra (253B) is ideal for multi-agent enterprise workflows requiring the highest accuracy.
Nemotron is part of the NVIDIA Avatar Cloud Engine (ACE) platform, along with Riva for speech development; and Audio2Face for generating realistic facial expressions.
Example use cases:
- Virtual assistants
- Customer service chatbots
NeMo
NVIDIA NeMo is a comprehensive toolkit for managing the AI agent lifecycle, primarily for models built with the NVIDIA Nemotron framework. It incudes a number of microservices - Curator cleans, filters, and deduplicates massive datasets, ensuring high-quality training data. Data Designer helps generate synthetic data from scratch to maximise training efficiency. Retriever helps extract text, tables, charts, and images from PDFs and databases within your business. Next, Evaluator is used to benchmark and test models, whilst the Agent Toolkit monitors autonomous agents, improving reliability and performance. Lastly, Guardrails allows developers to add safety, security, and topical constraints.
Once your agentic AI model is deployed, RL and Customiser drive constant optimisation with reinforcement learning techniques and fine-tuning to align models with domain data.
Example use cases:
- Ensuring virtual assistants remain up to date
- Managing Nemotron-based customer service chatbots

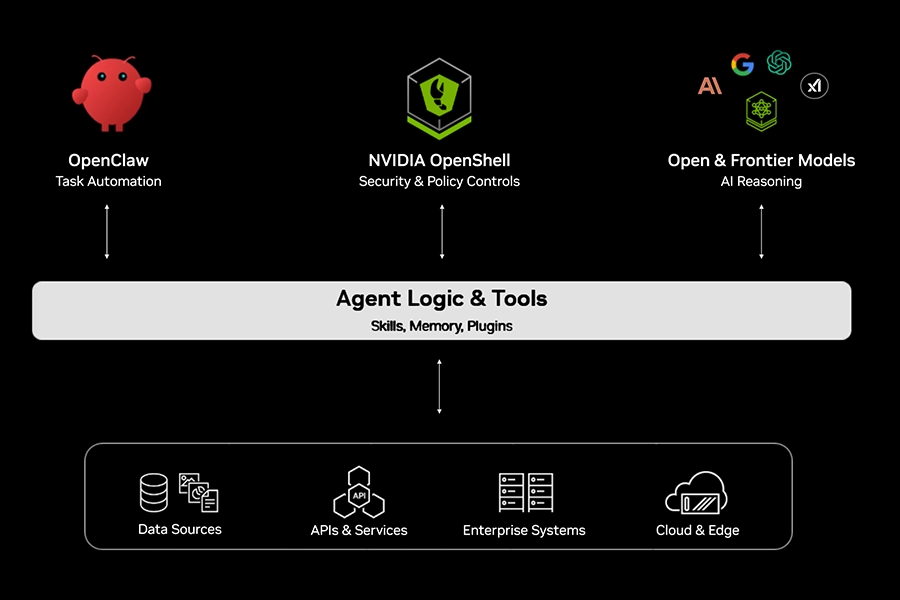
NemoClaw
NVIDIA NemoClaw is an open source framework that adds privacy and security controls to OpenClaw — a popular autonomous AI agent that runs locally to automate complex, multi-step tasks across your computer, files, and messaging apps. It works by installing NVIDIA OpenShell to enforce policy-based guardrails, effectively sandboxing each OpenClaw session including data handling controls and audit logging. NemoClaw also evaluates available compute resources to run high-performance models such as NVIDIA Nemotron locally for enhanced privacy and cost efficiency.
NemoClaw secures autonomous agents on systems including NVIDIA GeForce RTX PCs and laptops; RTX Studio PCs and laptops, RTX PRO workstations and laptops, DGX Spark, DGX Station and all RTX-powered cloud instances.
Example use cases:
- Enhanced productivity for customer service operators
- Streamlined workflows for IT support functions
- Cybersecurity teams monitoring employee 'always-on' AI agents
Riva
NVIDIA Riva is an SDK for building and deploying fully customisable, real-time conversational AI applications. It enables developers to integrate automatic speech recognition (ASR), text-to-speech (TTS), and neural machine translation (NMT) into their visual and audio workflows, with language support in English, Arabic, French, German, Hindi, Italian, Japanese, Korean, Mandarin, Portuguese, Russian, and Spanish; and with under 300ms latency for natural free-flowing conversations. Riva can also combine speech AI with visual cues, such as gaze detection and gestures, for a more contextual conversational experience.
Models can be trained on proprietary datasets using NVIDIA NeMo to adapt to specific vocabularies, accents, and domains, improving accuracy for specific use cases. As it is fully containerised, Riva can be deployed on-premise, in the cloud, or on edge devices containing NVIDIA Jetson GPUs, ensuring complete data privacy.
Example use cases:
- Virtual assistants
- Telehealth appointments
- Presenting livestreams

Content Generation
AI agents designed for text, image or video generation, or a combination of all three. The frameworks below contain tools and libraries for developing generative AI content for gaming, broadcast, streaming and more.
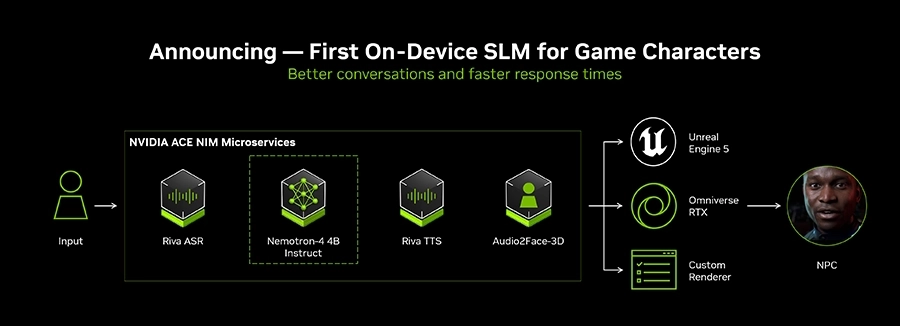
ACE
NVIDIA ACE (Avatar Cloud Engine) is a suite of generative AI technologies designed for game developers to create smart, conversational, and animated non-playable characters (NPCs). It includes several frameworks — Audio2Face that generates digital humans with dynamic facial animations, emotions and accurate lip syncing; Riva to understand human language with translation for up to 36 languages; and Nemotron LLMs to provide background stories and contextually aware responses for humanlike conversations. ACE also features multi-modal small language models (SLMs) that allow NPC characters to perceive their environment, plan actions, and act autonomously.
Supported in the NVIDIA Omniverse collaborative cloud platform, ACE also offers plug-ins for Unreal Engine and Autodesk Maya.
Example use cases:
- Development of NPCs in games
NeMo
NVIDIA NeMo is a comprehensive toolkit for managing the AI agent lifecycle, primarily for models built with the NVIDIA Nemotron framework. It includes several microservices - Curator is a component used to clean, filter, and deduplicate massive datasets to ensure high-quality training data. Data Designer helps generate synthetic data from scratch to maximise training efficiency. Retriever helps extract text, tables, charts, and images from PDFs and databases within your business. Evaluator is used to benchmark and test models. Agent Toolkit monitors autonomous agents, improving reliability and performance. Lastly, Guardrails enables developers to add safety, security and topical constraints.
Once your agentic AI model is deployed, RL and Customiser drive constant optimisation with reinforcement learning techniques and fine-tuning to align models with domain data.
Example use cases:
- Managing AI generated NPCs in games
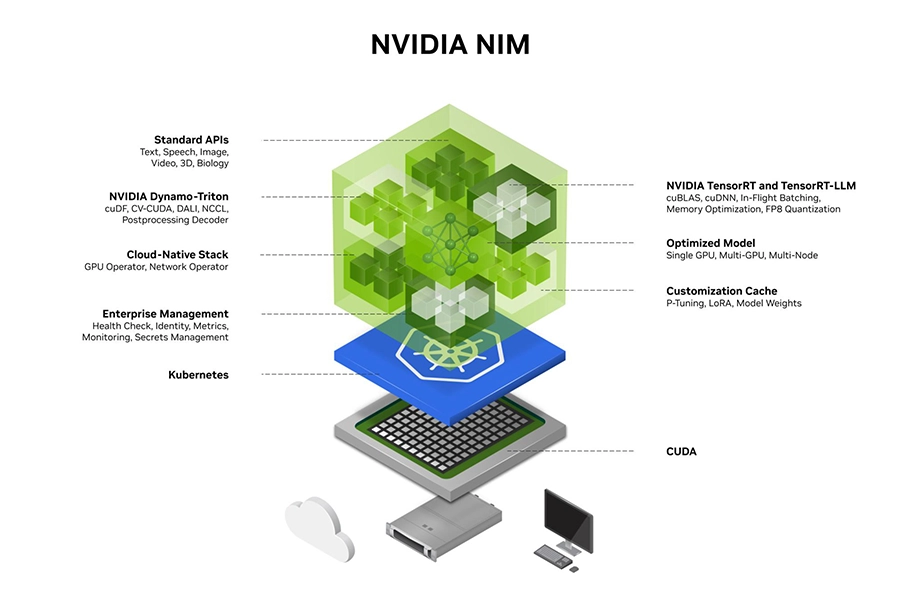
NIM
NVIDIA NIM (NVIDIA Inference Microservices) is a set of containerised, pre-built, and optimised software designed to accelerate the deployment of generative AI models, whether they be text, image or video based. Microservices include TensorRT-LLM which accelerates and optimises the inference performance of LLMs on NVIDIA GPUs resulting in higher throughput and lower latency. Similarly, Triton Inference Server optimises GPU utilisation through dynamic batching of incoming requests.
As NIMs are continuously updated with the latest optimised inference engines, you can expect to see performance on the same infrastructure improving over time.
Example use cases:
- Deployment of digital avatars in games or customer service applications
- Gain improvements in real-time computer vision tasks (image classification / object detection)
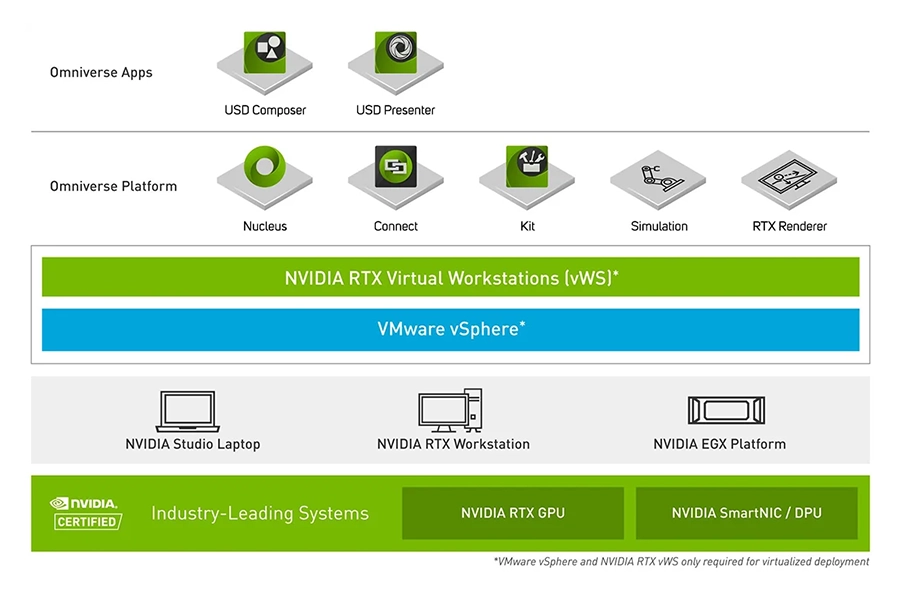
Omniverse
NVIDIA Omniverse is a cloud computing platform that enhances 3D visualisation and development workflows, providing a collaborative space accessible by multiple users. It obeys real-world physics, ensuring simulations are as accurate as possible, guaranteeing their integrity when transferred to the real world. It utilises a common USD (Universal Scene Description) format, making collaboration across multiple third-party applications powerful and yet straight-forward.
Omniverse is a key part of many AI workflows, offering digital twin environments for safe simulation and learning, prior to real world deployment.
Example use cases:
- Robotic and autonomous vehicle simulations with physically accurate worlds
- Design and modelling of industrial facilities or entire smart cities
- Synthetic data generation
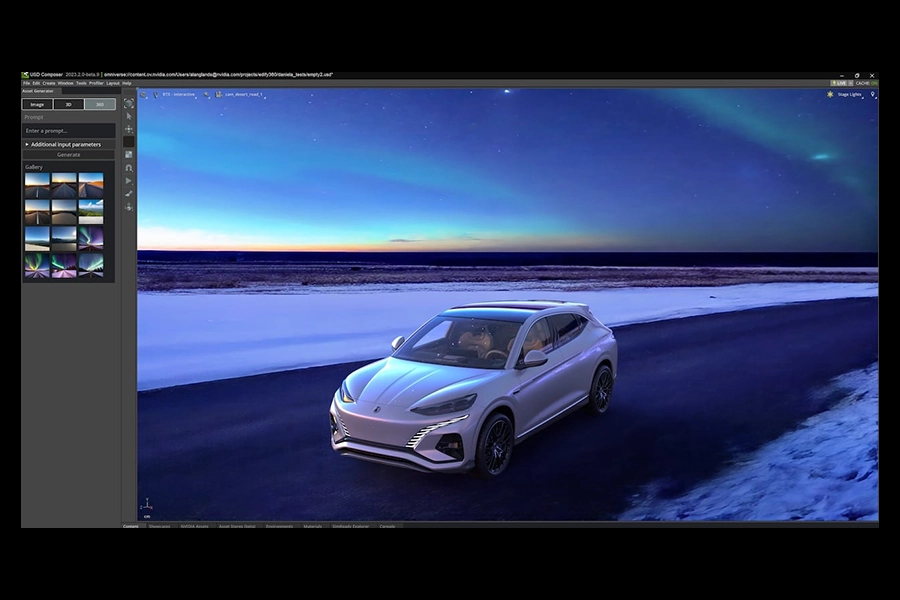
Picasso
NVIDIA Picasso is a DGX Cloud native application for building and deploying generative AI-powered image, video, and 3D applications. It offers advanced text-to-image, text-to-video, text-to-3D and 2D to 3D capabilities, utilising the NVIDIA Edify architecture used in Omniverse, and trained on licensed, safe data from sources including Shutterstock, Adobe and Getty Images.
From simple text prompts, Picasso can generate custom 360-degree, up to 8K-resolution, high-dynamic-range (HDR) images, which can be used as a base to set a background or custom light a scene.
Example use cases:
- Generating props, characters, and environmental assets for games or virtual environments
- Create custom, marketing content quickly
- Rapid architectural visualisation
Data Analytics
AI agents designed for data analytics are designed to work seamlessly within existing workflows such as Python and Apache Spark, often requiring minimal or zero code changes for acceleration. NVIDIA AI Enterprise software ensures these tools are secure, supported, and ready for production deployment. The frameworks below contain tools and libraries for advanced data, graph, image and video analytics.
Cosmos
NVIDIA Cosmos generates world foundation models (WFMs), using advanced video analytics, enabling developers to create, simulate, and understand complex physical environments — real or synthetic — to train and validate physical AI models. While it is primarily designed as a platform for physical AI (robotics and autonomous vehicles), its capabilities including an inbuilt 7B VLM make it ideal for analysing and organising large-scale visual data resulting in a range of uses in industrial, safety and logistics environments. These attributes enable users to instantly query large-scale video datasets and retrieve specific scenarios for analysis.
As Cosmos is designed for physics-based, geospatially accurate simulations, it is supported in NVIDIA Omniverse environments to render photorealistic data.
Example use cases:
- Interpretation of realtime or recorded video streams
- Traffic monitoring
- Generation of predictive AI worlds
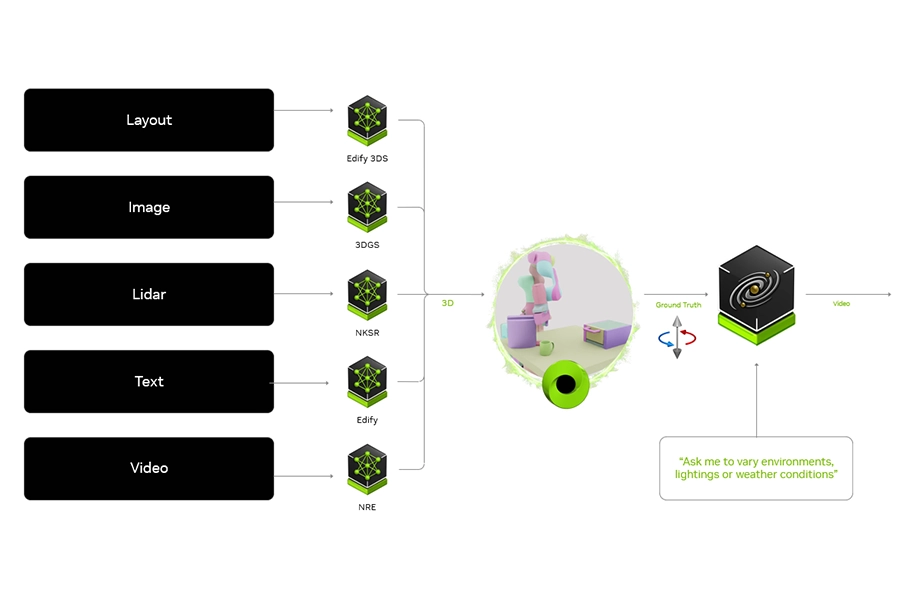
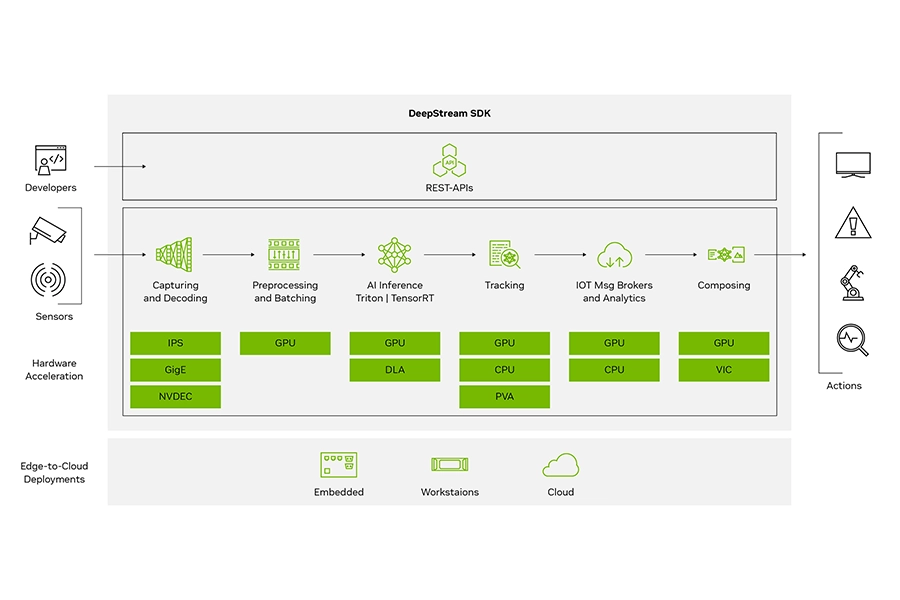
DeepStream
NVIDIA DeepStream is an SDK designed to build AI-powered, real-time video, audio and image processing applications. It is ideal for data analytics as it performs computer vision tasks such as object detection, people counting and tracking, and classification on video feeds. It works by turning raw visual data into actionable insights for retail, traffic management, and industrial automation. It includes over 40 hardware-accelerated plug-ins and 30 sample applications and extensions to optimise pre/post processing, inference and multi-camera tracking.
DeepStream bridges the gap between edge devices such as NVIDIA Jetson and the cloud, allowing analytics to be processed locally. The analysed metadata can be sent to analytics engines for further analysis, reporting, or storage.
Example use cases:
- Analysing customer traffic, aisle flow, and inventory
- Traffic management, parking detection, and safety monitoring
- Defect detection and worker safety
Merlin
NVIDIA Merlin is an open source recommender systems framework, designed to streamline the building of recommenders by addressing common preprocessing, feature engineering, training, and inference challenges. Merlin consists of several specialised libraries designed to handle different stages of the recommendation pipelines — each optimised to support the retrieval, filtering, scoring and ordering of data — all controlled through easy-to-use APIs.
Merlin is capable of pre-processing terabyte-scale datasets on GPUs up to 10x faster than CPU-based Apache Spark models, delivering much improved data analysis at scale.
Example use cases:
- End-to-end pipeline data optimisation
- Embedding massive data tables that exceed GPU memory
- Building models that predict user actions based on short-term session data
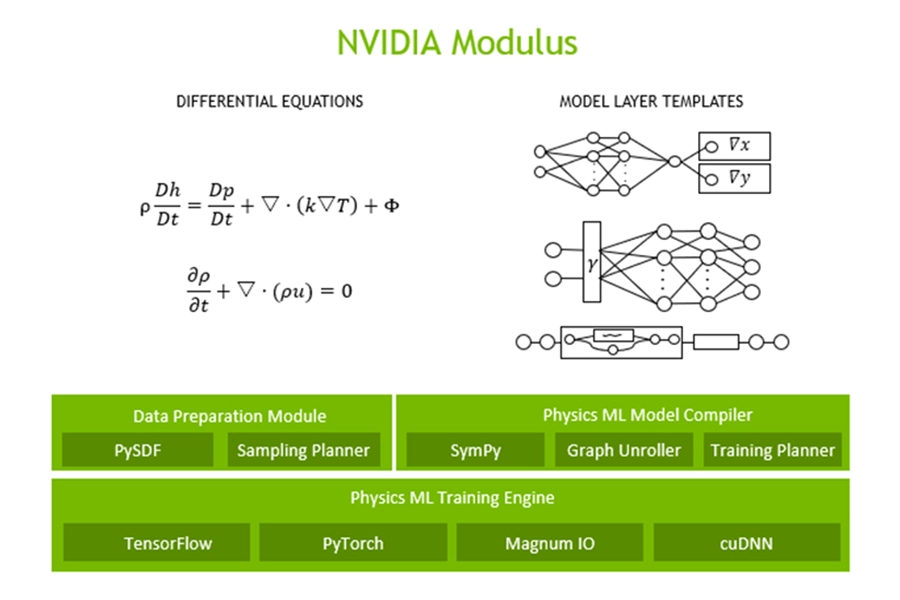
Modulus
NVIDIA Modulus is an open-source deep-learning framework designed to build, train, and deploy AI models that simulate the physical world. It bridges the gap between traditional physics, including fluid dynamics and structural mechanics, and AI, allowing engineers to create real-time digital twins and predictive models. Using Physics-Informed Neural Networks (PINNs), it embeds the laws of physics directly into the training of the neural network.
Modulus also takes historical or simulated data from traditional computer-aided engineering (CAE) tools, such as Ansys, and uses AI to drastically speed up calculations.
Example use cases:
- Acceleration of interactive simulations for digital twins using PhysicsNeMo NIM
- Ingestion of physics-grounded datasets from real-world sensors such as satellites
- Design of heatsinks, microchips, and electronics cooling systems where heat distribution modelling is key
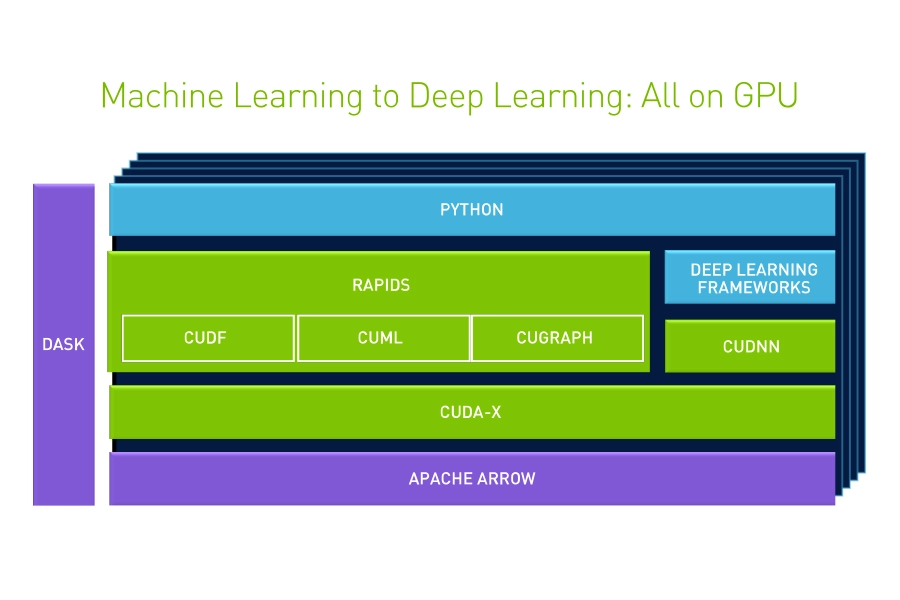
RAPIDS
NVIDIA RAPIDS is an open-source suite of GPU-accelerated Python libraries designed to speed up end-to-end data science and analytics pipelines. It is designed for large-scale data manipulation offering performance gains of up to 40x–150x over traditional CPU-based workflows. RAPIDS enables the entire data science pipeline to run on the GPU, avoiding the time-consuming bottlenecks of moving data between CPU and GPU. Additionally, because RAPIDS is designed to feel like the standard Python PyData ecosystem, data scientists can leverage GPU power without learning CUDA programming.
RAPIDS also supports multi-node, multi-GPU deployments, making it suitable for distributed processing on large datasets.
Example use cases:
- Faster data manipulation and larger dataset handling
- Process large-scale data science workloads on GPUs rather than CPUs
- RAPIDS plug-in for Apache Spark for performance gains or reduction in cloud costs
Healthcare
AI agents deployed for healthcare provide accelerated computing platforms and AI models that enable faster drug discovery, improve medical diagnostics, and promote efficient hospital workflows. The frameworks below contain tools and libraries for developing AI agents that aim to improve patient outcomes whilst retaining dignity and confidentiality.
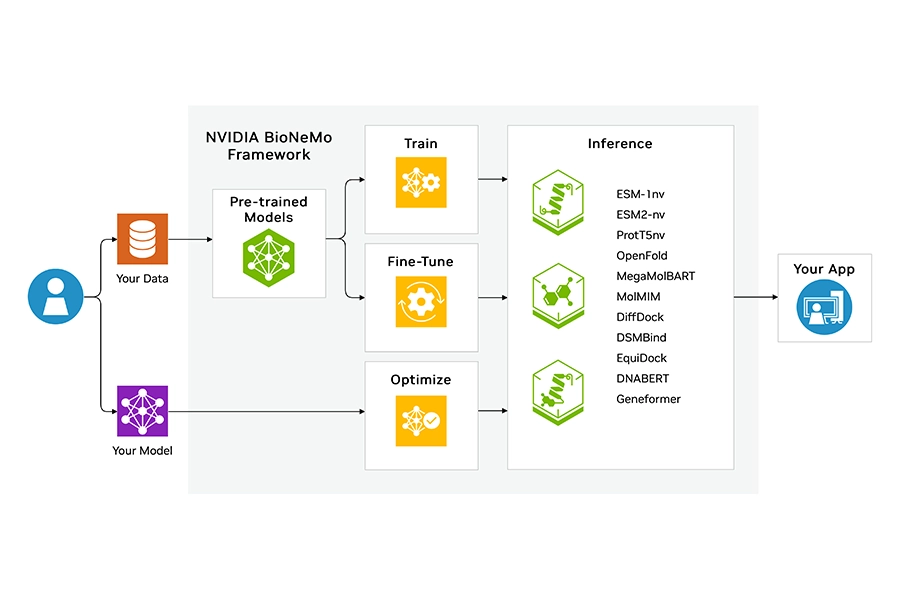
BioNeMo
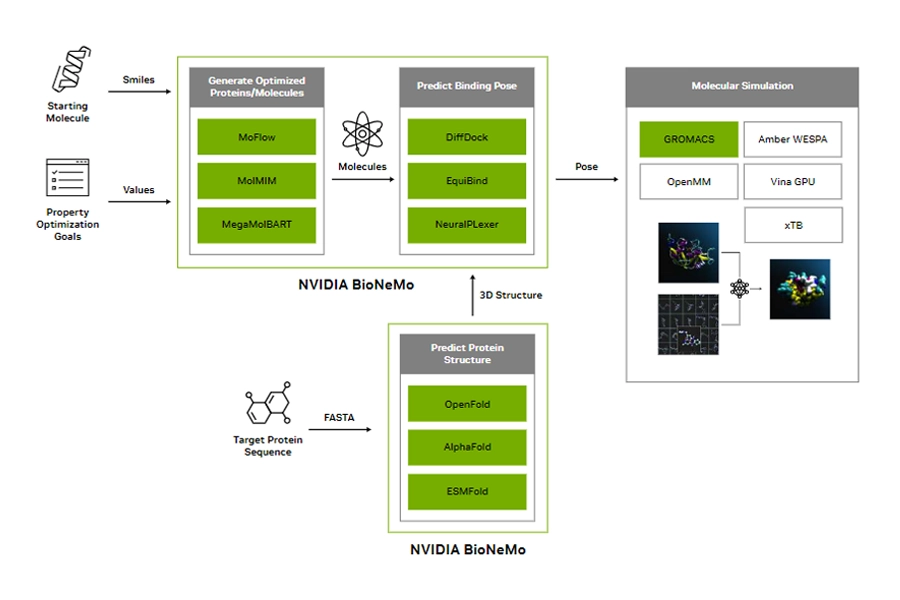
NVIDIA BioNeMo is a generative AI framework and development platform specifically designed for computational drug discovery and life sciences. It accelerates the research and development of biomolecular AI models, such as protein structure prediction, antibody and peptide design, small molecular generation, and RNA modelling. It features state-of-the-art pre-trained models for protein-protein complex formation, protein structure prediction, and molecular generation.
The BioNeMo framework is optimised to run on GPU-accelerated clusters and includes NIMs that enable inference of production-grade biomolecular foundation models across on-premise, hosted or cloud platforms.
Example use cases:
- Generation of new chemical entities with desired properties
- Predicting binding sites by 3D modelling of amino acids
- Accelerating lab data analysis
Clara Discovery
NVIDIA Clara Discovery — part of the Clara healthcare platform — is a collection of frameworks, applications, and AI models enabling GPU-accelerated computational drug discovery. It brings GPU-acceleration to computational chemistry, genomics, and imaging; and AI and machine learning to genomics, proteomics, microscopy, virtual screening, visualisation, clinical imaging and natural language processing.
Clara Discovery supports genomic workflows with Clara Parabricks, medical imaging with Clara Imaging and drug discovery with BioNeMo.
Example use cases:
- Generative AI for drug discovery
- Predictive modelling using digital twins for drug manufacture
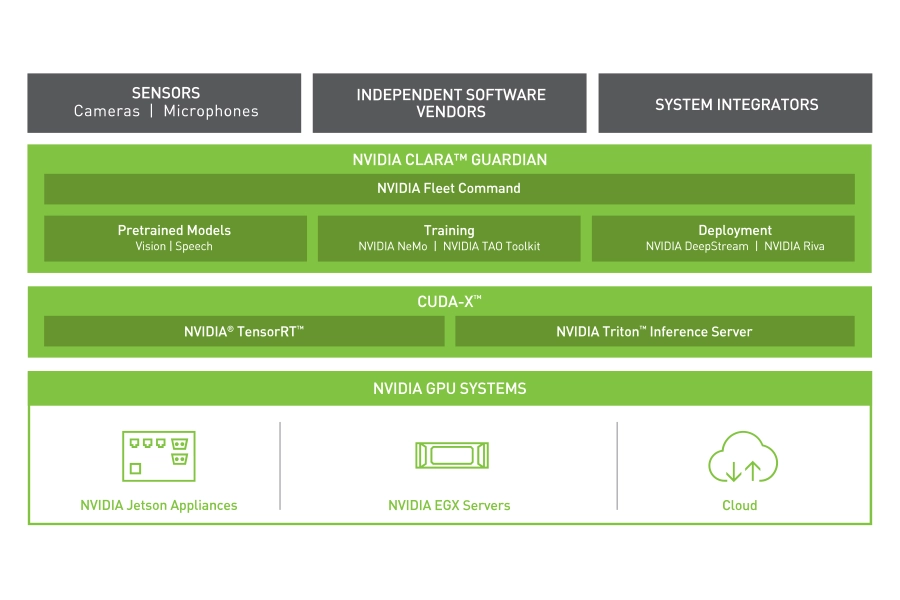
Clara Guardian
NVIDIA Clara Guardian — part of the Clara healthcare platform — is a framework that simplifies the development and deployment of smart sensors within a healthcare facility. Its key components include automated speech recognition, text-to-speech and natural language understanding; alongside healthcare-specific versions of Riva and DeepStream for computer vision. Also included is NVIDIA Fleet Command, a hybrid-cloud platform for securely managing and scaling AI deployments across servers and edge devices at hospitals.
The open source nature of these frameworks makes it easy for third-party partners to add AI capabilities to common sensors used in medical environments.
Example use cases:
- Management of PPE usage or social distancing
- Body temperature checking
- Heart rate estimation and gesture recognition models for patient monitoring
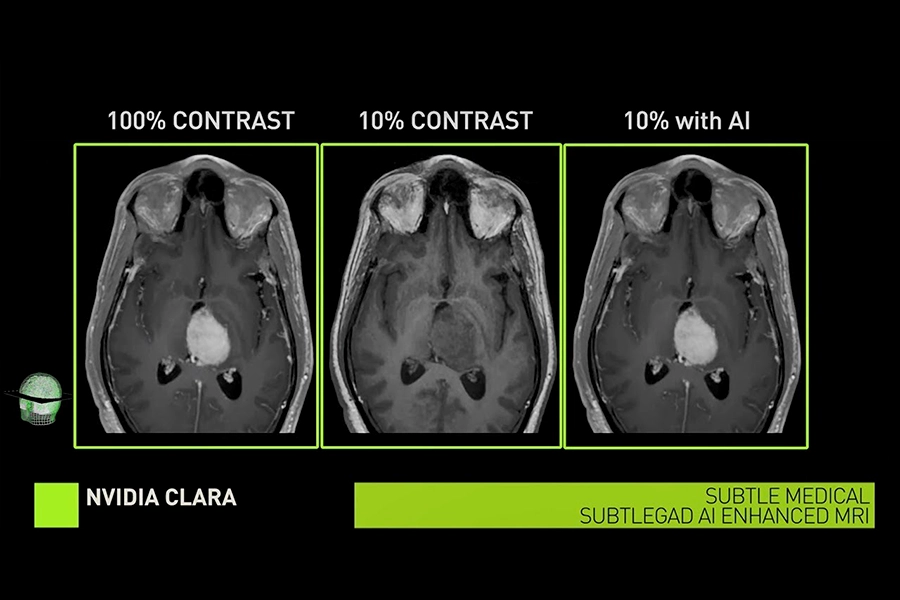
Clara Imaging
NVIDIA Clara Imaging — part of the Clara healthcare platform — is a framework including pre-trained models and software libraries to accelerate image processing, analysis, and reconstruction for diagnostics from X-ray, CT, MRI, and ultrasound scans. It enables developers to create, train, and deploy advanced imaging models for tasks such as image segmentation, classification, and 3D visualisation.
One component of the framework, Clara Reason, provides step-by-step reasoning for image interpretation, acting as a "second reader" for radiologists to validate findings and build trust in AI assessments.
Example use cases:
- Creating realistic 3D visualisations of anatomy for improved diagnostics
- AI-assisted annotation to speed up the labelling of imaging data
- Image enhancement and reconstruction to improve image quality and reduce noise
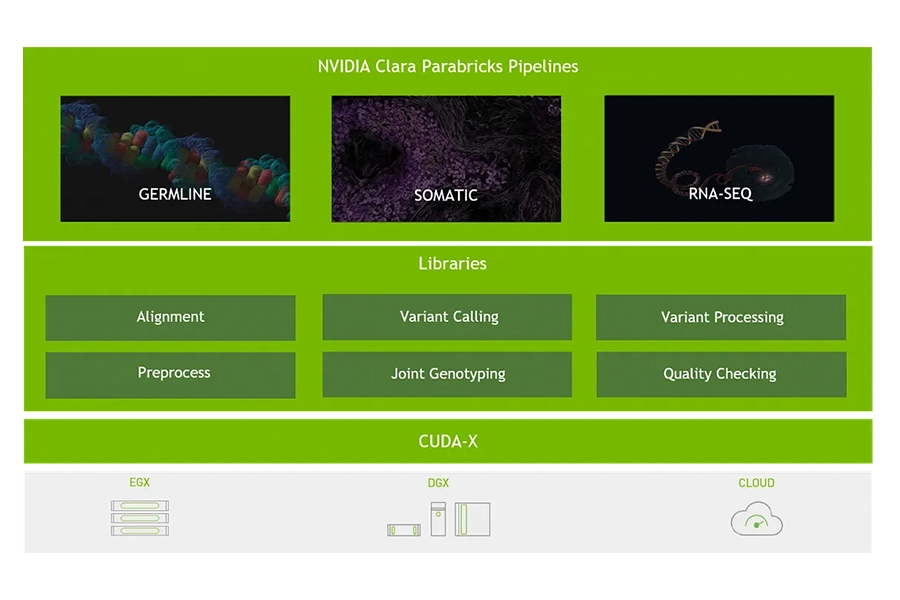
Clara Parabricks
NVIDIA Clara Parabricks — part of the Clara healthcare platform — is a scalable genomics software suite for secondary analysis of RNA and DNA, that provides GPU-accelerated versions of trusted, open source tools. Compatible with leading sequencing instruments, it can be used across diverse bioinformatics workflows to increase speed and reduce cost, while enhancing accuracy and ensuring transparency.
Reducing time to results for researchers, Parabricks offers whole genomic sequencing in around 45 minutes as opposed to 30 hours with CPU-only solutions.
Example use cases:
- Genomic sequencing to accelerate drug discovery
- Large scale population analysis
- Rapid analysis of clinical samples
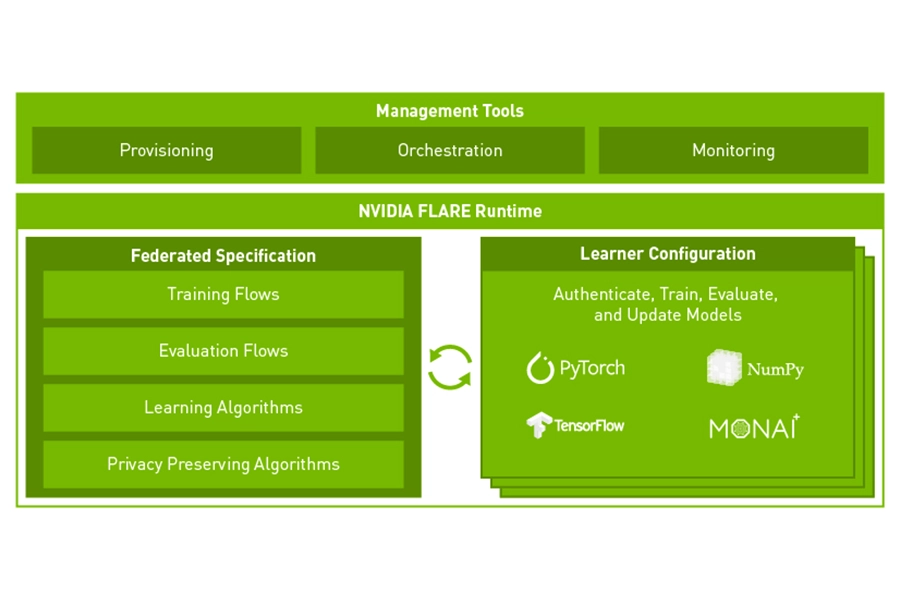
FLARE
NVIDIA FLARE (Federated Learning Application Runtime Environment) is an SDK that enables secure, privacy-preserving federated learning across multiple parties. Federated learning is a way to develop and validate more accurate and generalisable AI models from diverse data sources by mitigating the risk of compromising data security or privacy. It enables AI models to be built with a consortium of data providers without the data ever leaving the individual site.
FLARE also includes built-in tools for managing SSL certificates, user authentication, and access authorisation, for when data governance is critical.
Example use cases:
- Analysis of city- or county-wide data from multiple hospitals for patient trends
- Rapid analysis across geographies for disease outbreaks such as COVID-19
- Developing AI models for specific diseases with large datasets from multiple sources
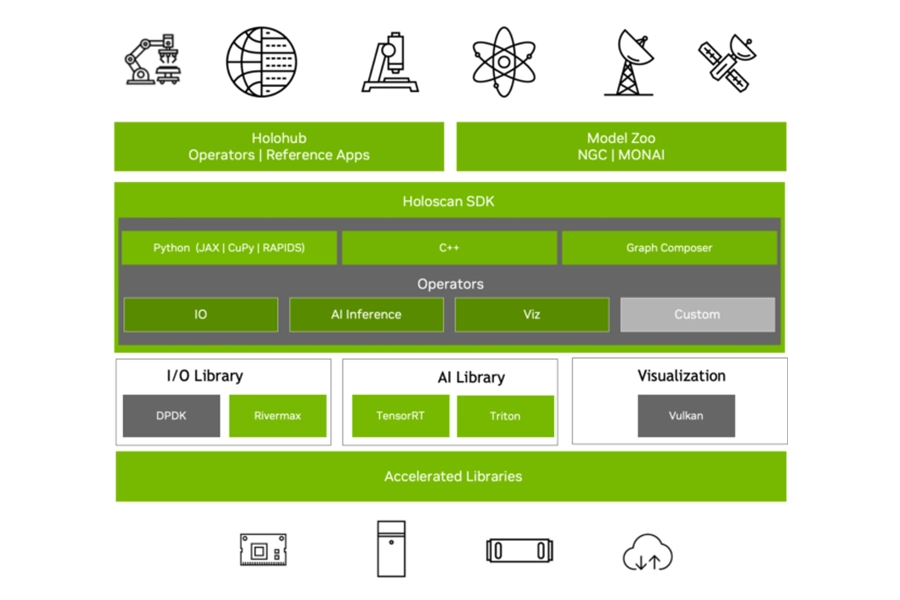
Holoscan
NVIDIA Holoscan is a multimodal, AI sensor processing platform designed for realtime, low-latency streaming applications at the edge and in the cloud. It provides a full-stack infrastructure — combining hardware, software, and AI libraries — to build, deploy, and manage AI-enabled pipelines for medical devices. Holoscan employs NVIDIA Rivermax network streaming and GPUDirect RDMA technologies to bypass the CPU for faster data transfer, resulting in end-to-end latency as low as 10ms, essential in applications such as realtime surgical video.
The Holoscan SDK accelerates deployment on NVIDIA Jetson modules for development of production-ready, industrial-grade AI-powered medical hardware.
Example use cases:
- Realtime tool tracking to assist surgeons by detecting anatomy during operations
- 3D surgical guidance to help stereo depth estimation in procedures and training
- Enhancing patient safety during procedures
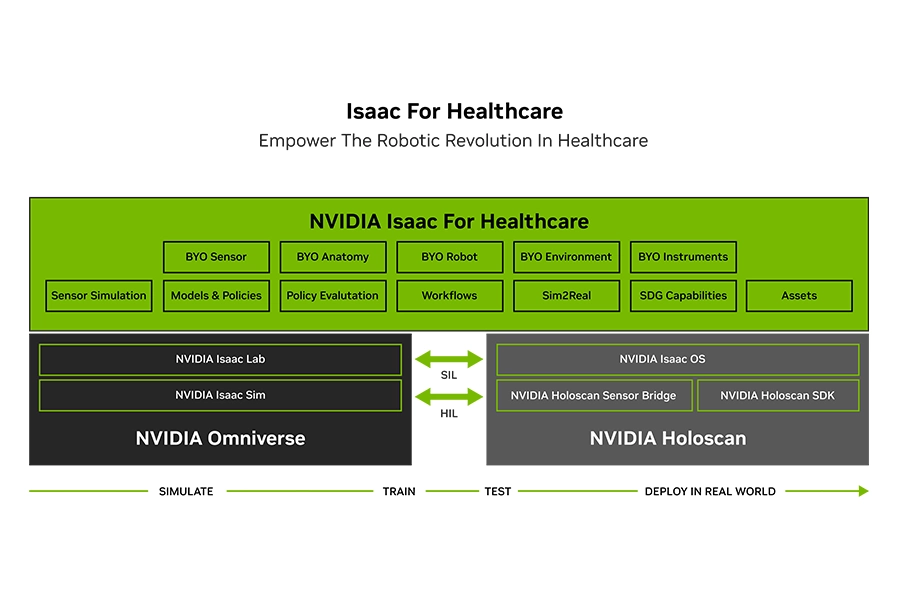
Isaac for Healthcare
NVIDIA Isaac for Healthcare is a purpose-built platform containing tools that provide pre-trained AI models, simulation environments, and accelerated libraries for medical and assistive robotics. It supports developers across the entire workflow — from collecting and curating data to building and testing AI models in realistic simulated medical environments, where robots can practice medical tasks virtually, learn from their mistakes using reinforcement learning, and then transfer those learned policies directly to physical machines.
As patient data is often hard to gather or privacy-restricted, Isaac for Healthcare allows developers to generate photorealistic, physically accurate synthetic data to train their AI on a massive scale.
Example use cases:
- Digital prototyping of next-gen healthcare robotic systems, sensors, and instruments
- Training robotic policies for augmented dexterity for use in robot-assisted surgery
- Synthetic data generation for medical environment simulation
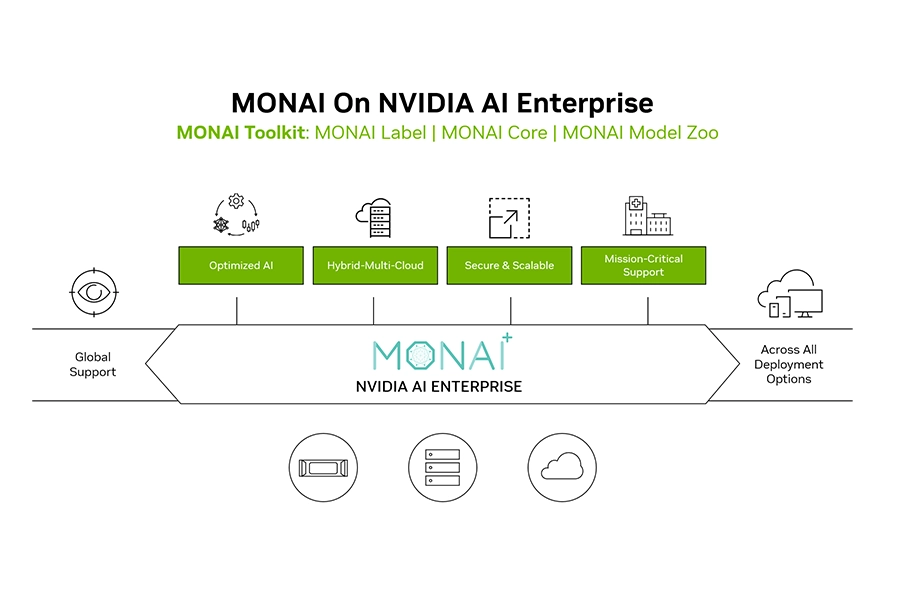
MONAI Toolkit
The NVIDIA MONAI Toolkit is a containerised, enterprise-grade development environment that accelerates the development, training, and deployment of AI medical imaging models. Built upon the open-source Medical Open Network for AI (MONAI) framework — co-founded by NVIDIA — the toolkit includes pre-trained models and libraries specifically optimised for healthcare AI workloads on NVIDIA GPUs. It provides a secure, scalable workflow supported within NVIDIA AI Enterprise (NVAIE), making it suitable for commercial application development.
MONAI Core provides a training framework for medical imaging that supports 3D segmentation, classification and detection. MONAI Deploy supports turning trained AI models into packaged applications for easy integration into clinical environments.
Example use cases:
- AI-assisted intelligent medical data labelling
- Building AI models for accelerated medical imaging analysis for specific diagnoses
IT Infrastructure
AI agents deployed for IT infrastructure optimise, secure, and manage modern IT and datacentre architectures. By leveraging GPUs, networking hardware, and native software, these applications reduce downtime, maximise hardware utilisation, and automate complex IT operation.
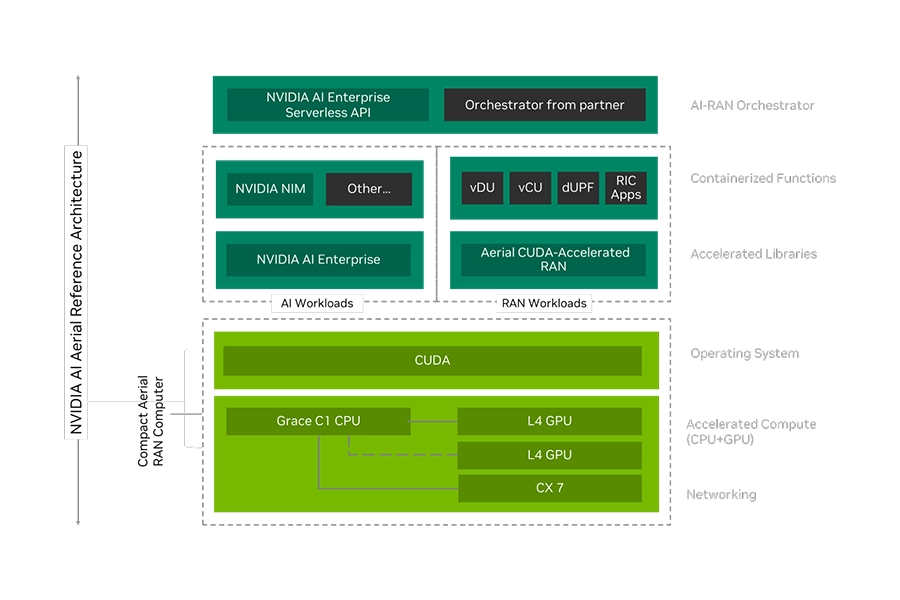
AI Aerial
NVIDIA AI Aerial is an accelerated computing platform that integrates wireless networks (5G / 6G) and AI workloads on the same IT infrastructure by implementing a virtual radio access network (vRAN). It transforms standard telecom towers and edge servers into software-defined, AI-native datacentres, enabling operators to run telecom functions and AI applications simultaneously on shared GPU.
It includes the Aerial Omniverse Digital Twin to simulate and validate complex signal propagation, tower placements, and network loads virtually before deploying physical infrastructure.
Example use cases:
- Design of 5G / 6G mast deployments across campuses or entire cities
- Dynamic multi-tenant GPUs handle peak telecom network demands (vRAN) during the day and shift compute power to generative AI or edge inference during off-peak hours
FLARE
NVIDIA FLARE (Federated Learning Application Runtime Environment) is an SDK designed to enable secure, privacy-preserving federated learning across multiple parties. Federated learning is a way to develop and validate more accurate and generalisable AI models from diverse data sources by mitigating the risk of compromising data security or privacy. It enables AI models to be built with a consortium of data providers without the data ever leaving the individual site.
FLARE also includes built-in tools for managing SSL certificates, user authentication, and access authorisation, for when data governance is critical.
Example use cases:
- Seamless scaling across Docker and Kubernetes containerised environments
- Deployment and automatic configuration of infrastructure-as-code on cloud providers such as AWS and Azure
Holoscan
NVIDIA Holoscan is a multimodal, AI sensor processing platform for realtime, low-latency streaming applications at the edge and in the cloud. It provides a full-stack infrastructure — combining hardware, software, and AI libraries — to build, deploy, and manage AI-enabled pipelines for real-time streaming data applications. Holoscan employs NVIDIA Rivermax network streaming and GPUDirect RDMA technologies to bypass the CPU for faster data transfer, resulting in end-to-end latency as low as 10ms.
The Holoscan SDK accelerates deployment on NVIDIA Jetson modules for development of production-ready, industrial-grade AI-powered hardware.
Example use cases:
- Processing of live video feeds on the same shared AI infrastructure that manages broadcast graphics, dynamic sports analytics or redundancy failover
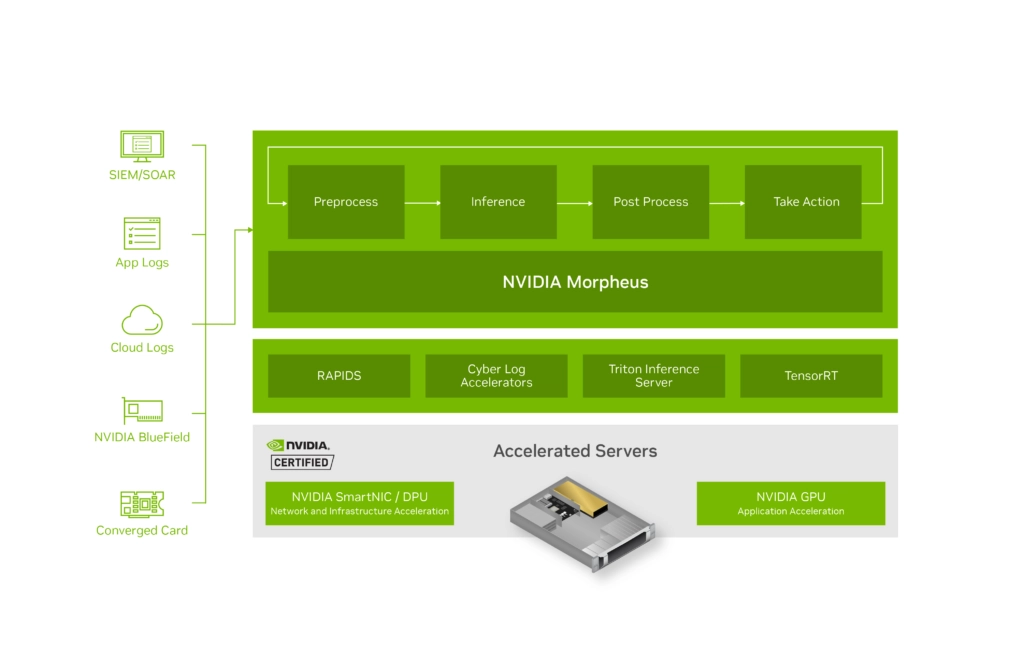
Morpheus
NVIDIA Morpheus is a framework for enterprise cybersecurity and IT infrastructure. It utilises unsupervised machine learning to inspect network traffic, analyse logs, and identify security threats or system anomalies in realtime, transforming cybersecurity from a reactive measure into a proactive, data-driven science. Creating a unique model for the typical behaviour of every user, service, account, and machine across your entire network, it allows the system to flag subtle, anomalous interactions the moment they happen.
Morpheus integrates directly with NVIDIA BlueField DPUs to inspect all IP traffic across the datacentre fabric instantaneously, without causing bottlenecks.
Example use cases:
- Realtime network telemetry and digital "fingerprinting" of every user
- Data loss protection and Spear Phish detection
- Zero trust automation
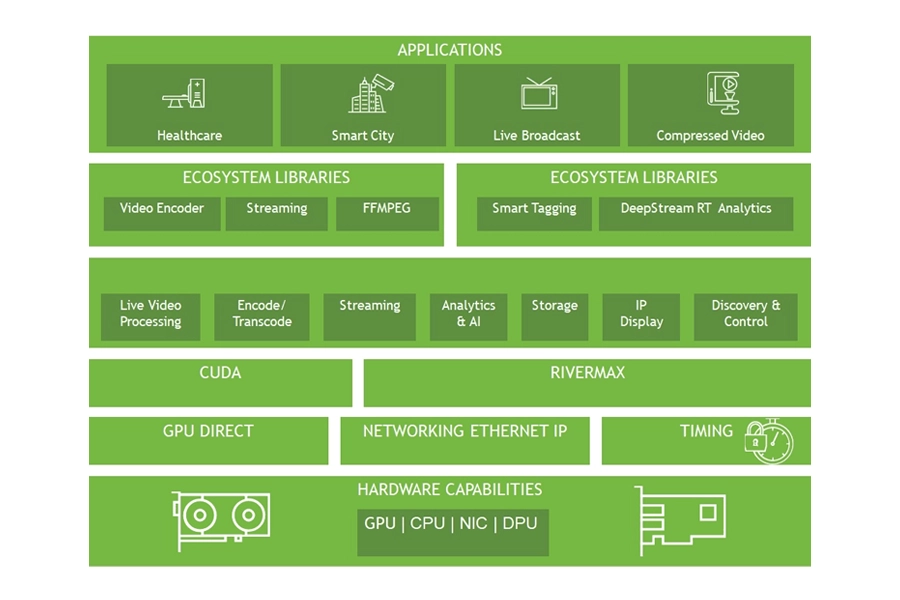
Rivermax
NVIDIA Rivermax is an optimised networking SDK that enables ultra-low-latency, zero-copy data streaming directly from standard IP networks into GPU memory, bypassing the operating system kernel. It offloads the packet processing overhead to accelerate massive streaming workloads, lowering CPU utilisation while maintaining synchronisation, optimising streaming throughput across standard 10, 25, 50, and 100Gb/s networks.
Rivermax leverages NVIDIA ConnectX adapters and BlueField DPUs to manage packet-level headers and deliver precise hardware-based Precision Time Protocol (PTP) synchronisation.
Example use cases:
- Ultra-low latency for algorithmic and high-frequency financial trading platforms
- Powering rendering nodes for large-scale immersive environments and virtual production workflows
- Assistance with ingesting massive real-time data sets for AI
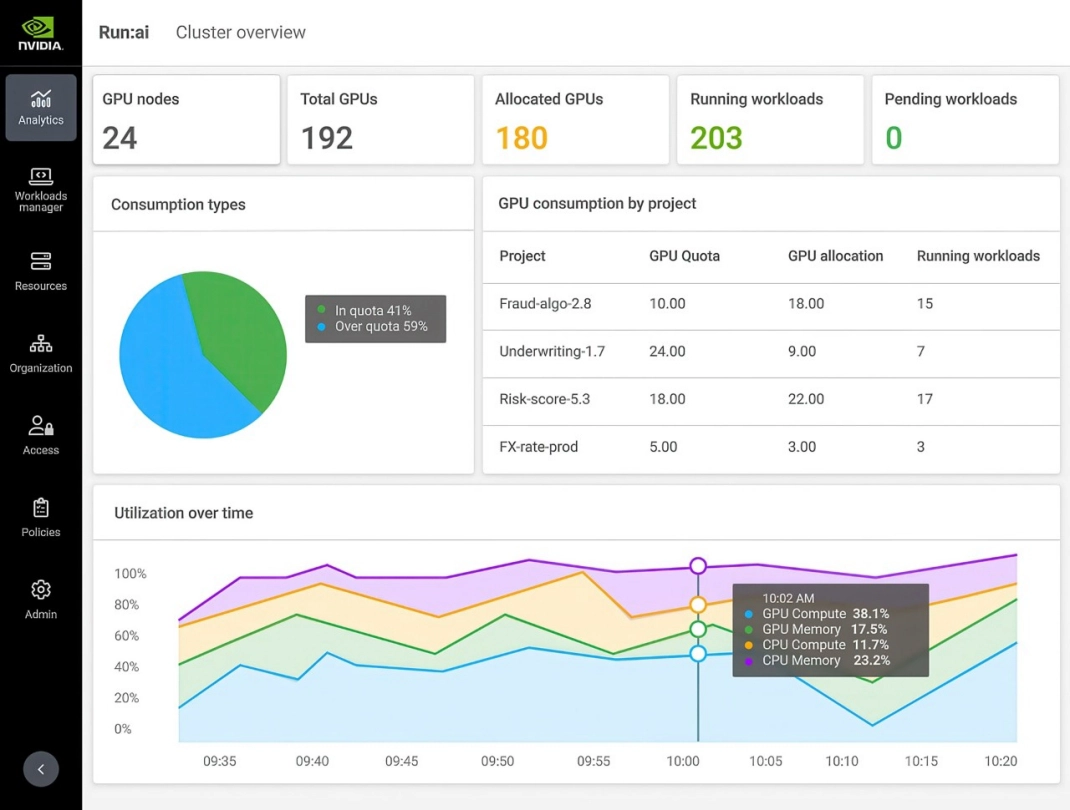
Run:ai
NVIDIA Run:ai is a Kubernetes-native platform that orchestrates and optimises GPU resources for AI workloads. It aggregates isolated GPUs across the entire datacentre into a single, shared, elastic pool, maximising utilisation through fractional allocation. It automatically queues, prioritises, and preempts jobs to ensure high-priority AI training or inference tasks get the compute they need when they need it, whilst enforcing strict governance rules across on-premises, hybrid, or multi-cloud AI infrastructure.
Run:ai also provides IT administrators with detailed dashboards to manage quotas, track usage, and control project-level access.
Example use cases:
- Dynamic resource pooling & allocation to maximise GPU utilisation
- Enforcing GPU governance and quotas
- Optimising inference tasks in conjunction with NIMs
Slurm
NVIDIA Slurm (Simple Linux Utility for Resource Management) is an open source cluster management and job scheduling system for Linux. It supports granular GPU scheduling, allowing you to request specific numbers, architectures (Hopper, Blackwell), and exact configurations of GPUs, whilst coordinating shared memory, interconnect bandwidth (NVLink), and node topology to eliminate network bottlenecks during distributed AI training runs.
Slurm can effectively enforce strict fair-share queues, preemptive priority jobs, and customised workload policies, across clusters of thousands of GPUs.
Example use cases:
- Coordination of multi-node GPU communication during massive AI model training
- Ensuring fair allocation of GPU resource amongst teams
- Hyperscale AI — Slurm handles AI training orchestration, while Kubernetes handles the deployment and inference serving of the resulting models

TAO
NVIDIA TAO (Train, Adapt, Optimise) is a low-code framework that simplifies deep learning by abstracting complex code. It provides customisable pre-trained AI vision, vision foundation, depth estimation and multimodal models with domain-specific data, optimising them for fast edge or cloud deployment without needing deep AI expertise. It can be deployed across numerous NVIDIA platforms including Jetson, RTX PRO, MGX, HGX and DGX servers.
Once TAO finishes training and optimising a model, it exports the model in ONNX or TensorRT engine formats, so users can then deploy inference models using Triton Inference Server NIM or the DeepStream SDK.
Example use cases:
- Adapt object detection models to monitor server health and track unauthorised access in datacentres
- Fine-tune vision models without needing massive volumes of training data
- Compress heavy neural networks to run on smaller Jetson compute nodes

Robotics & Physical AI
AI agents deployed for physical AI are designed to provide a unified, end-to-end platform for building, training, and deploying AI-powered robots and autonomous vehicles.
Cosmos
NVIDIA Cosmos generates world foundation models (WFMs), using advanced video analytics, to create, simulate, and understand complex physical environments — real or synthetic — to train and validate physical AI models. While it is primarily designed as a platform for Physical AI (robotics and autonomous vehicles), its capabilities include an inbuilt 7B VLM making it ideal for analysing and organising large-scale visual data, resulting in a range of uses in industrial, safety, and logistics environments.
As Cosmos is designed for physics-based, geospatially accurate simulations, it is supported in NVIDIA Omniverse environments to render photorealistic data.
Example use cases:
- Testing how different algorithmic versions for physical AI systems perform in virtual settings
- Synthetic data generation to create photorealistic, physics-based environments
- Foresight simulation generating multiple potential future outcomes based on a system's current state
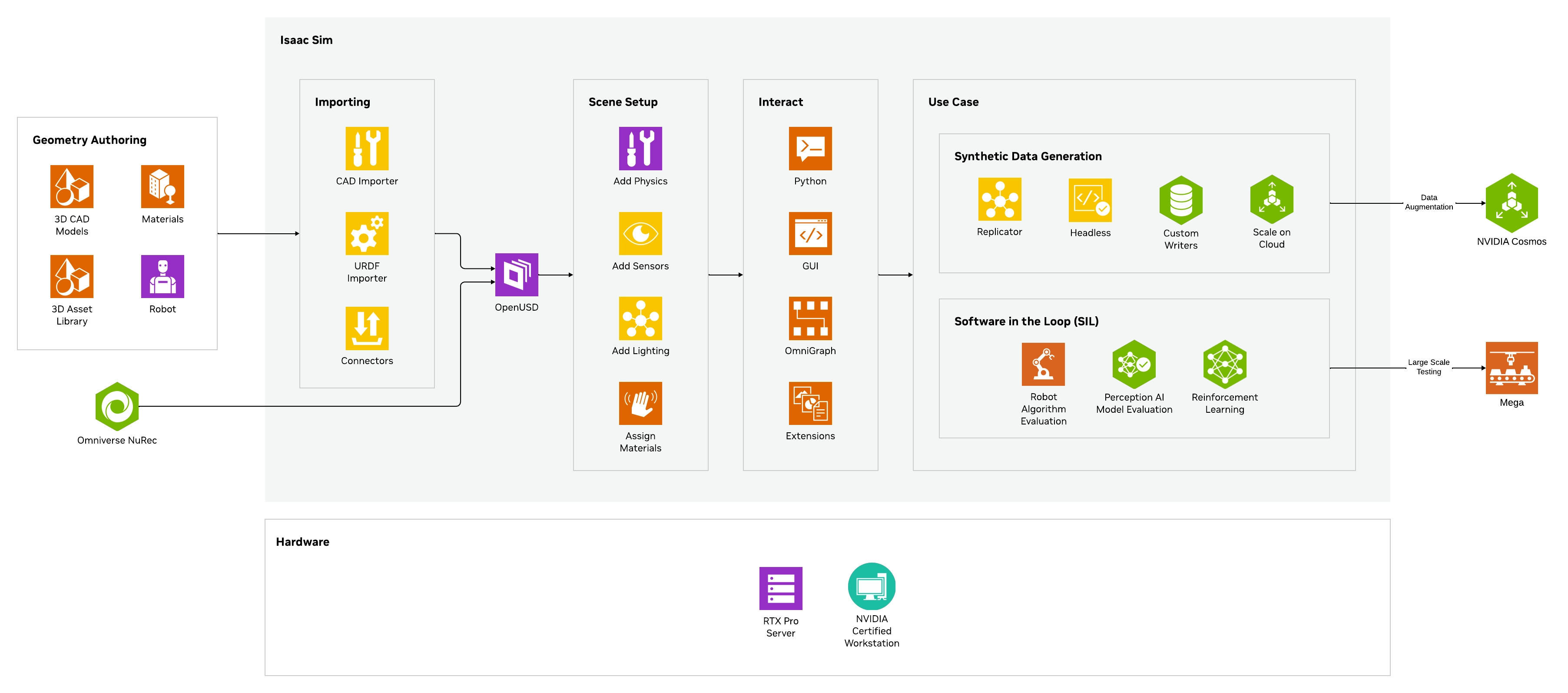
Isaac Sim
NVIDIA Isaac Sim is a physically accurate robotics simulation platform built on the NVIDIA Omniverse platform. It allows developers to design, test, train, and deploy AI-driven robots in photorealistic virtual environments before building them in the real world. It allows the testing of robotic systems without potential real-world damage or danger; and the simulation of various sensors, including LiDAR, ultrasonic sensors, and RGB / depth cameras for model training.
Isaac Sim can also automatically generate labelled data for AI training, solving real-world data shortages; and it pairs with Isaac Lab for reinforcement learning so robots can learn how to walk, grasp, or navigate.
Example use cases:
- Design, testing and training of AI-powered robots in a virtual world
- Synthetic data generation to create photorealistic, perfectly labelled synthetic images of environments such as warehouses or factory floors
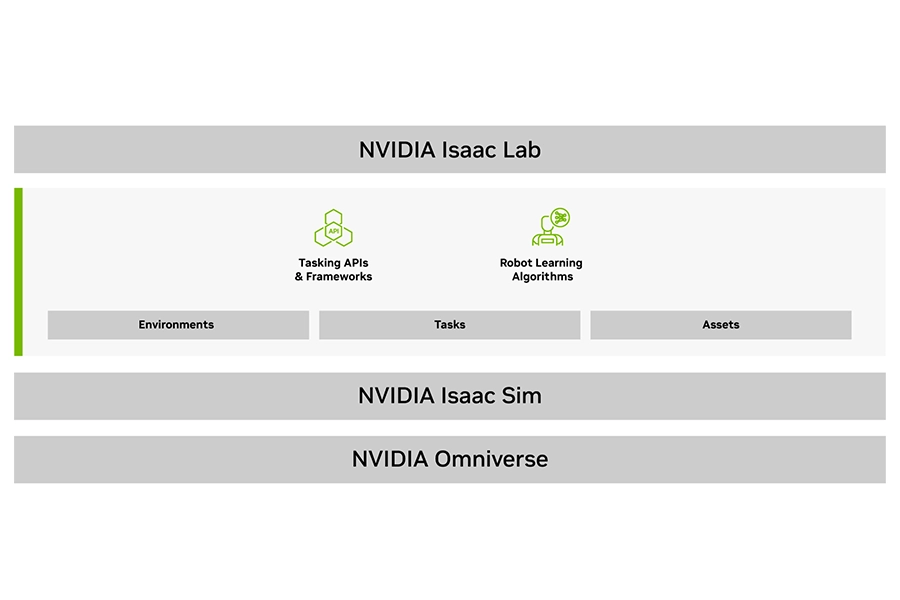
Isaac Lab
NVIDIA Isaac Lab is an open-source, modular framework for training robotic policies at scale using reinforcement and imitation learning. It provides developers with GPU-accelerated physics and high-fidelity sensor simulations to rapidly teach robots how to grasp and manipulate objects; or walk, navigate, avoid obstacles and cope with unpredictable terrain. Built on NVIDIA Isaac Sim, it leverages photorealistic rendering with highly accurate physics to make sim-to-real training seamless.
Isaac Lab also serves as the foundational robot learning framework of the NVIDIA Isaac ROS and GR00T platforms.
Example use cases:
- Locomotion training for humanoid and quadruped robots
- Training robotic arms and artificial hands to grasp objects, perform precise industrial assembly, and safely interact with deformable objects
- Simulation-to-real deployment with trial-and-error cycles porting directly into physical robots
Isaac ROS
NVIDIA Isaac ROS (Robot Operating System) is a low-level, modular perception and navigation framework built on the ROS 2 open framework. It includes ready-to-use packages for common tasks for optimal performance. It leverages NVIDIA hardware to provide advanced, real-time spatial awareness for object tracking, depth estimation, and 6D pose estimation, enabling developers to build faster, smarter, and more efficient robots by deploying models directly on embedded NVIDIA Jetson GPUs.
Although Isaac ROS acts as a general use platform for robotic development, Isaac GR00T is considered a specialised framework for whole body control in advanced humanoids.
Example use cases:
- Creating highly accurate maps and calculating exact positions using cameras and lidar
- Object detection and segmentation to identify obstacles, humans, or specific objects in real-time

Isaac GR00T
NVIDIA Isaac GR00T (Generalist Robot 00 Technology) is a comprehensive development platform and open foundation model for accelerating the creation of general-purpose humanoid robots. It integrates with Isaac Lab and Omniverse to act as the brain and development ecosystem that enables robots to process text, voice, video, and prior human demonstrations to break down complex instructions and execute them with human-like reasoning.
GR00T uses a "thinking fast and slow" approach where a slow-thinking system reasons and plans the correct actions, while a fast-thinking system translates those plans into precise, continuous, whole-body physical movements.
Example use cases:
- Synthetic motion generation using minimal real-world human demonstrations to create large synthetic datasets
- NLP allows humanoid robots to break down complex, multi-step instructions and execute them using common sense
- Virtual reality teleoperation enables operators to remotely control robots in realtime within digital twins
Modulus
NVIDIA Modulus is an open-source deep learning framework for building, training, and deploying AI models that simulate the physical world. It bridges the gap between traditional physics, including fluid dynamics and structural mechanics, and AI, enabling engineers to create realtime digital twins and predictive models. Using Physics-Informed Neural Networks (PINNs), it embeds the laws of physics directly into the training of the neural network.
Modulus also takes historical or simulated data from traditional CAE tools such as Ansys, and uses AI to drastically speed up calculations.
Example use cases:
- Acceleration of interactive simulations for digital twins using PhysicsNeMo NIM
- Ingestion of physics-grounded datasets from real-world sensors such as satellites
- Design of heatsinks, microchips, and electronics cooling systems where heat distribution modelling is key
Omniverse
NVIDIA Omniverse is a cloud computing platform that enhances 3D visualisation and development workflows, providing a collaborative space accessible by multiple users. It obeys real-world physics, ensuring simulations are as accurate as possible, guaranteeing their integrity when transferred to the real world. It utilises a common USD (Universal Scene Description) format, making collaboration across multiple third-party applications powerful and yet straightforward.
Omniverse is a key part of many AI workflows, offering digital twin environments for safe simulation and learning, prior to real world deployment.
Example use cases:
- Robotic and autonomous vehicle simulations with physically accurate worlds
- Design and modelling of industrial facilities or entire smart cities
- Synthetic data generation
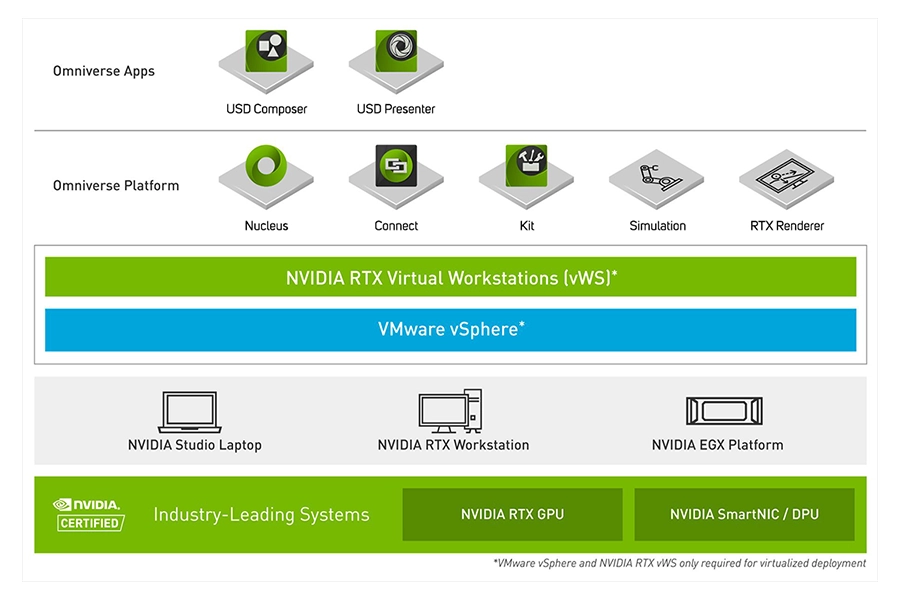
Smart Cities
AI agents deployed for smart cities including computing engines and developer frameworks focusing on video analytics and digital twins. Through edge AI and simulation, municipalities can automate traffic flow, optimise energy consumption, and enhance public safety.
AI Aerial
NVIDIA AI Aerial is an accelerated computing platform that integrates wireless networks (5G / 6G) and AI workloads on the same IT infrastructure by implementing a virtual radio access network (vRAN). It transforms standard telecom towers and edge servers into software-defined, AI-native datacentres, allowing operators to run telecom functions and AI applications simultaneously on shared GPU.
It includes the Aerial Omniverse Digital Twin to simulate and validate complex signal propagation, tower placements, and network loads virtually before deploying physical infrastructure.
Example use cases:
- Design of 5G / 6G mast deployments across campuses or entire cities
- Dynamic multi-tenant GPUs handle peak telecom network demands (vRAN) during the day and shift compute power to generative AI or edge inference during off-peak hours
Cosmos
NVIDIA Cosmos generates world foundation models (WFMs), using advanced video analytics, to create, simulate, and understand complex physical environments — real or synthetic — to train and validate physical AI models. While it is primarily designed as a platform for Physical AI (robotics and autonomous vehicles), its capabilities include an inbuilt 7B VLM making it ideal for analysing and organising large-scale visual data, resulting in a range of uses in industrial, safety, and logistics environments.
As Cosmos is designed for physics-based, geospatially accurate simulations, it is supported in NVIDIA Omniverse environments to render photorealistic data.
Example use cases:
- Testing how different algorithmic versions for physical AI systems perform in virtual settings
- Synthetic data generation to create photorealistic, physics-based environments
- Foresight simulation generating multiple potential future outcomes based on a system's current state
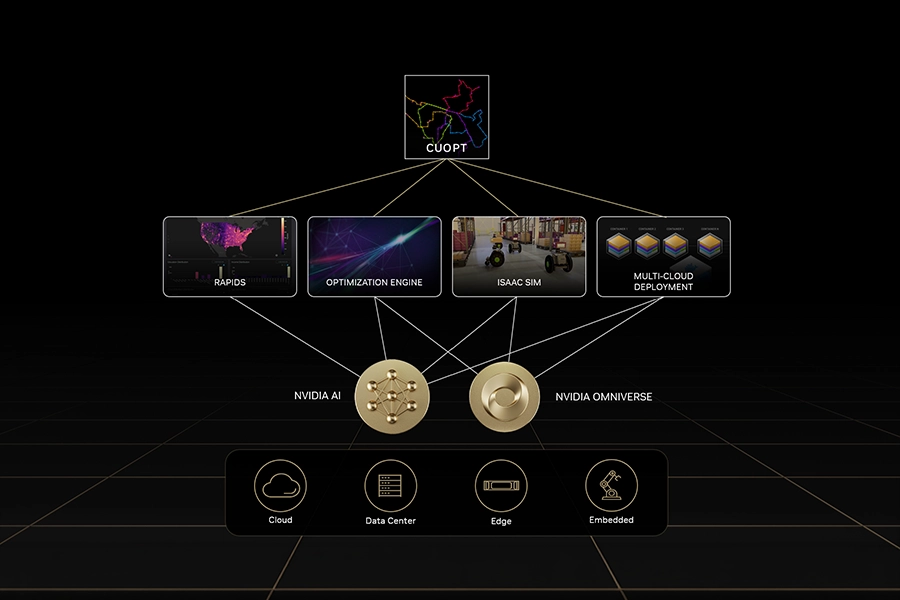
cuOpt
NVIDIA cuOpt is an open-source, GPU-accelerated engine designed for decision optimisation and complex mathematical problem-solving. It enables organisations to calculate highly complex operational plans such as vehicle routing, supply chain logistics, and job scheduling, in near real-time. This allows businesses to solve large-scale problems and adapt to real-time supply chain disruptions in seconds.
cuOpt integrates with Omniverse, RAPIDS and the Isaac family of physical AI applications to provide seamless and visual planning.
Example use cases:
- Fleet optimisation by calculating the most efficient routes to reduce mileage, fuel consumption, and carbon emissions
- Job scheduling to maximise resources by optimally aligning tasks across workers, machines and shifts
- Balancing risk and return by optimising capital allocation across complex financial assets
DRIVE
NVIDIA DRIVE is an end-to-end AI platform for autonomous vehicles, advanced driver-assistance systems (ADAS), and digital cockpits. It combines hardware, software, and cloud infrastructure to enable cars to perceive their environment and drive safely without human intervention. It is made up of DRIVE AV, the software responsible for autonomous driving; and DRIVE IX, that manages the in-cabin experience, including driver monitoring, dashboard displays, and voice recognition.
DRIVE integrates with Omniverse and Cosmos to generate real-world simulations for different driving conditions and is deployed within vehicles using dedicated Jetson DRIVE AGX modules.
Example use cases:
- Creation of autonomous vehicles and intelligent cockpits
- Generative AI assistants that perceive, reason, and provide realtime assistance
- Development of active safety and parking functions

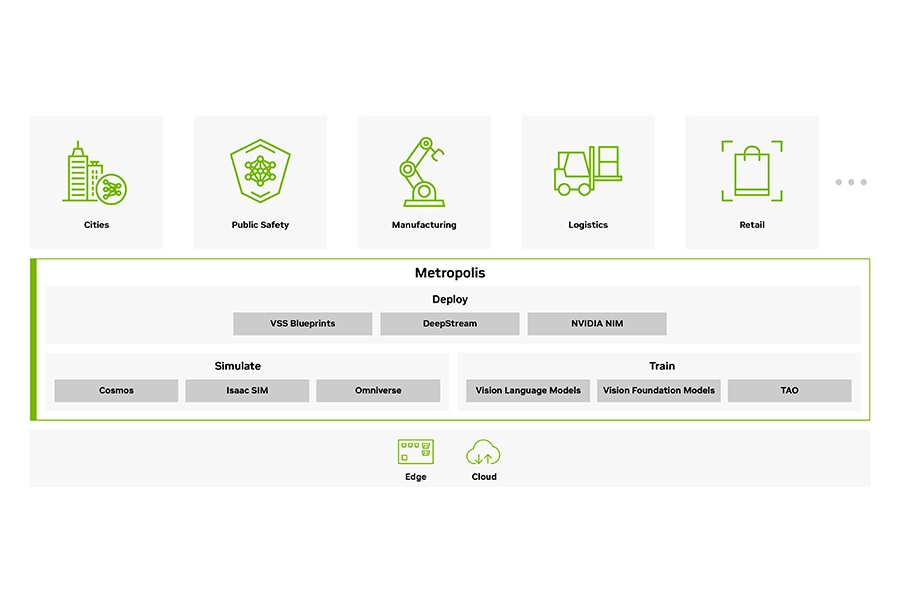
Metropolis
NVIDIA Metropolis is an application framework that brings visual AI to physical spaces. It simplifies the creation, deployment, and scaling of intelligent video analytics and computer vision agents — transforming raw video and sensor data from cameras into actionable, real-time insights, and provides the necessary tools for businesses and governments to build smart infrastructure across various sectors.
Metropolis is often deployed with Omniverse for advanced visualisation and colouration, and streamlined using the DeepStream SDK and NIMs.
Example use cases:
- Optimising traffic flow or public transport, detecting accidents, and enhancing public safety
- Monitoring assembly lines for defects, tracking inventory and ensuring workplace PPE compliance
- Analysing customer foot traffic, generating heat maps and automating checkout experiences
Omniverse
NVIDIA Omniverse is a cloud computing platform that enhances 3D visualisation and development workflows, providing a collaborative space accessible by multiple users. It obeys real-world physics, ensuring simulations are as accurate as possible, guaranteeing their integrity when transferred to the real world. It utilises a common USD (Universal Scene Description) format, making collaboration across multiple third-party applications powerful and yet straightforward.
Omniverse is a key part of many AI workflows, offering digital twin environments for safe simulation and learning, prior to real world deployment.
Example use cases:
- Robotic and autonomous vehicle simulations with physically accurate worlds
- Design and modelling of industrial facilities or entire smart cities
- Synthetic data generation
Multiple frameworks, libraries and SDKs may be required to tailor and fine-tune your final AI application. Scan and our consultancy partner MSBC Group can identify the most appropriate technology from open and closed sources and work with your existing infrastructure to minimise additional costs. We help design, build, test and validate your application and then scale it into production, to deliver the maximum ROI for your business.
Contact Us