FDL Europe 2021 - World Food Embeddings using Earth Observation

FDL Europe 2021
World Food Embeddings using Earth Observation
PUBLISHED 12 SEP 2022
FDL Europe is a public - private partnership between the European Space Agency (ESA), the University of Oxford, Trillium Technologies and leaders in commercial AI supported by Google Cloud, NVIDIA and Scan AI. FDL Europe works to apply AI technologies to space science, to push the frontiers of research and develop new tools to help solve some of the biggest challenges that humanity faces. These range from the effects of climate change to predicting space weather, from improving disaster response, to identifying meteorites that could hold the key to the history of our universe.
FDL Europe 2021 was a research sprint hosted by the University of Oxford that took place over a period of eight weeks in order to promote rapid learning and research outcomes in a collaborative atmosphere, pairing machine learning expertise with AI technologies and space science. The interdisciplinary teams address tightly defined problems and the format encourages rapid iteration and prototyping to create meaningful outputs to the space program and humanity.
World Food Embeddings using Earth Observation
Project Background
Feeding a growing global population in a changing climate presents a significant challenge to society. Projected crop yields in a range of agricultural and climatic scenarios depend on accurate crop maps to gauge food security prospects. Accurate information on the agricultural landscape obtained from remote sensing can help manage and improve agriculture and serve as the basis for yield forecasts. Large amounts of imagery and data are produced daily by an ever-growing multitude of earth observation satellites, however generating crop classification maps, especially in developing countries where information on the extent and types of crops is scarce, can be very challenging.
Developed regions such as Europe and North America have collected and labeled crop data for decades but these processes require costly surveying campaigns and such labeled archives are not generally produced in less developed regions. Since labelling in developing regions is often extremely sparse this makes it challenging to train supervised machine learning models to classify crops in satellite observations of these regions. Creating additional amounts of labeled data is also challenging as creating them is a highly time-consuming and error-prone task and data labelling can only be done by domain experts.
Deep learning methods have greatly advanced very recently in unsupervised settings when there are no labels and the FDL project team aimed at using them to exploit specific properties of agriculture and food applications, such as invariances in crops, seasons and regions. The team developed scalable data pipelines to produce semantically rich embeddings, lower dimensional representations, representing crop satellite imagery. Thanks to these embeddings, models could potentially be trained faster models for crop detection, better exploiting the few available labels, revealing the underlying time evolution structure of crops and address many other downstream applications yet to be discovered. The imagery required for these models is derived from the Sentinel2 satellites. Sentinel2 consists of two satellites in sun synchronous orbits, to be able to operate in sunlight, where the data is delivered as tiles of 10,980 x 10,980 pixels and 12 optical bands, each pixel representing a 10m x 10m land square. Some tiles are overlapping and adjacent locations may be covered by tiles on the same orbit or on different orbits and thus times, but roughly each location is revisited every 5-10 days.
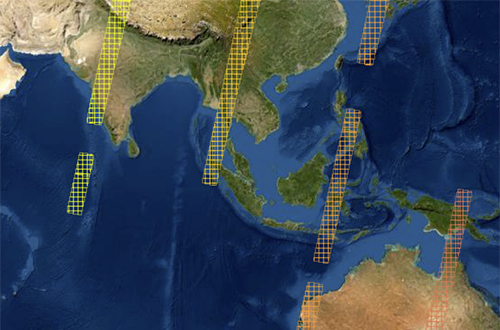
Project Approach
The diagram below shows the overall scheme for building predictive models in a setting where a self-supervised model is targeted at a certain pretext task, possibly trained with large amounts of unlabelled data. The pretext training precedes a supervised training for a downstream task. The pretext task is intended to contribute to the solution of the downstream task by providing the input data with a higher semantic information content compared to its original raw form. One must be able to define the pretext task by using the existing unlabelled data, trying to capture some invariance that can later be exploited in solving the downstream task.
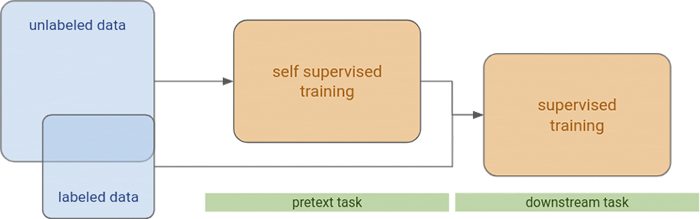
The supervised setting for the downstream task may exploit the results of the self-supervised setting in two different ways:
- As pre-training: by sharing part of the model architecture and transferring weights into the supervised setting as doing fine tuning on the reduced labeled dataset
- As embeddings: by producing a more semantically concise representation of an input image, typically in the form of a vector of a certain length. This representation intends to capture whatever the pretext task was set forth - for instance, in a setting where we have satellite image data as a time series (revisits) of images for each location in several bands, we could have pretext tasks aimed at producing similar embeddings for spatially close by revisits (time invariance), or for specific months where crops are known to cycle (seasonal invariance).
In the case of the embeddings, these were addressed to capture certain invariances or representational semantics at different levels, with respect to space and time. From the spatial perspective they included:
- Pixel level embeddings: each pixel in the image gets a vector embedding.
- Patch / chip level embeddings: the full patch gets a single vector embedding, summarising somehow the content of all its pixels.
- Entity level embeddings: a patch might contain different entities (such as different crop fields scattered throughout the patch), this way each entity (field) would get a different vector embedding. Different patches might contain different numbers of entities and, this, a different quantities of vector embeddings.
From the time perspective they included:
- Embeddings per revisit: each revisit gets its own embedding, whether it is at the pixel or patch level. Therefore, a time-series of revisits becomes a time-series of embeddings.
- Time-series embeddings: the full time-series gets a vector embedding.
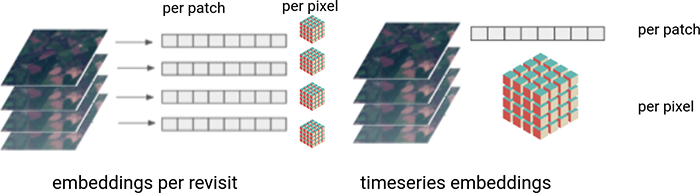
Depending on the choices above, different deep learning architectures would be more suitable or even feasible for models on the pretext and downstream tasks. For instance, segmentation architectures are more suitable to produce pixel level embeddings, which for instance might later be aggregated over entities (crop fields) or patches for a field classification downstream task, or may be used as such for a crop segmentation downstream task. On the other hand, convolutional architectures (reducing image dimensions) are more suitable to produce entity or patch level embeddings and classical machine learning methods (including multilayer perceptrons) can operate directly on entity or patch level embeddings to produce classifications or similarity measures.
Project Results
Using Momentum Contrast (MoCo) architectures, the FDL project team generated unsupervised embeddings to later use in a crop/no-crop classification downstream task. MoCo generated pixel level embeddings both per revisit (with 2d convolutions) and for a full time-series (with 3d convolutions), using different backbone architectures for the encoder.
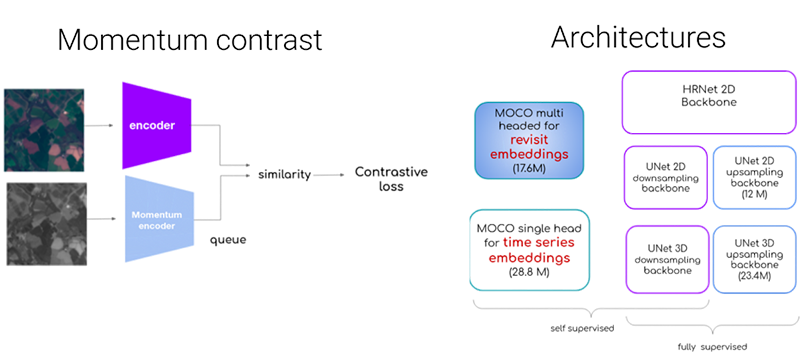
For the crop/no-crop downstream segmentation task carried out in Southern England, the team showed that with embeddings the dataset trains faster as seen below with the blue line showing with embeddings and the orange line without. For the visualisations, the underlying structures emerge, even if they are not so obvious in the mosaic of contiguous chips. Additionally, due to the nature of the contrastive task, similar colours signal similar embeddings, capturing spatial locations with similar time evolutions.

The FDL team carried out a wealth of experiments with different datasets and architectures, with different degrees of success. In general, the results suggest that designing pretext and downstream tasks must be done jointly and carefully, possibly with domain expert advice. It leaves the door open for further experiments and studies to follow. You can learn more about this case study by visiting the FDL EUROPE 2021 RESULTS PAGE, where a summary, poster and full technical memorandum can also be viewed and downloaded.
The Scan Partnership
Scan is a major supporter of FDL Europe, building on its participation in the previous year’s events. As an NVIDIA Elite Solution Provider Scan contributes multiple DGX supercomputers in order to facilitate much of the machine learning and deep learning development and training required during the research sprint period.
Project Wins
Demonstration that embeddings help train datasets faster, with results showing enhanced underlying structures
Time savings generated during eight-week research sprint due to access to GPU-accelerated DGX systems

James Parr
Founder, FDL / CEO, Trillium Technologies
"FDL has established an impressive success rate for applied AI research output at an exceptional pace. Research outcomes are regularly accepted to respected journals, presented at scientific conferences and have been deployed on NASA and ESA initiatives - and in space"

Dan Parkinson
Director of Collaboration, Scan
"We are proud to work with NVIDIA to support the FDL Europe research sprint with GPU-accelerated systems for the second year running. It is a huge privilege to be associated with such ground-breaking research efforts in light of the challenges we all face when it comes to climate change and extreme weather events."
Speak to an expert
You’ve seen how Scan continues to help FDL Europe further its research into the climate change and space. Contact our expert AI team to discuss your project requirements.
phone_iphone Phone: 01204 474747
mail Email: [email protected]
Related Content

FDL Europe 2021 - ML Onboard
Using AI and satellite imagery to identify extreme weather 'hot spots'.
Read More >
FDL Europe 2020 - Digital Twin Earth
Machine learning to make rain forecasting more accurate.
Read More >
FDL Europe 2020 - Clouds & Aerosols
Aerosol effects on mesoscale cloud structures in marine boundary layer clouds
Read More >