Oxford Robotics Institute - Using AI to Advance Robot Learning

Oxford Robotics Institute
Touching a NeRF: Leveraging Neural Radiance Fields for Tactile Sensory Data Generation
PUBLISHED 2 MAY 2023
The Oxford Robotics Institute (ORI) is built from collaborating and integrated groups of researchers, engineers and students all driven to change what robots can do for us. Their current interests are diverse, from flying to grasping - inspection to running - haptics to driving, and exploring to planning. This spectrum of interests leads to researching a broad span of technical topics, including machine learning and AI, computer vision, fabrication, multispectral sensing, perception and systems engineering.
Touching a NeRF: Leveraging Neural Radiance Fields for Tactile Sensory Data Generation
Project Background
Humans rely heavily on tactile sensing for tasks such as identifying and grasping objects - for example, retrieving car keys from a pocket - and in this context, tactile sensing is fundamental to gain information or properties of the object such as its roughness or stiffness. This sensing is also able to complement vision in occluded scenarios [1, 2]. Tactile sensing is also critical for robotics applications such as manipulation and control [3] and object or texture recognition [4]. These tactile-based object recognition tasks are usually tackled with machine learning methods that typically require large amounts of data for training [1, 5, 6]. However, collecting this data is challenging as the robot needs to physically interact with the environment and the object. While cameras can capture the overall shape of an object, they cannot produce tactile data.
Recent studies have shown that Red, Green, Blue plus Depth (RGB-D) images contain rich sensory information that can be used to generate tactile data [7-9]. Given a camera or depth image of the object surface it is possible to generate the corresponding tactile sensor attributes. One limitation of these vision-based generative approaches is that they require the collection of visual samples at given positions and orientations to generate the corresponding synthetic tactile data [7].
Project Approach
A Neural Radiance Field (NeRF) is a model for synthesising novel views of scenes [10]. It requires a set of RGB images and their associated camera poses for training. A trained NeRF is able to synthesise high-quality and novel views of the modelled scene. After using the NeRF model to render the RGB-D images of an object from a target camera pose, the goal is to generate the corresponding tactile image, where the tactile sensor orientation is the same as the camera orientation, and the tactile sensor position is along the centre camera ray. To achieve this, the ORI team employed a conditional Generative Adversarial Network (cGAN) to learn the mapping between a rendered RGB-D image x, on one hand and the corresponding tactile image y, on the other [12]. Building on previous work [8], the team then modified the cGAN model to condition the generative model on the RGB image, the depth image and a reference background image, using separate encoders, with skip-connections added between the encoder for the reference background image and the generator.
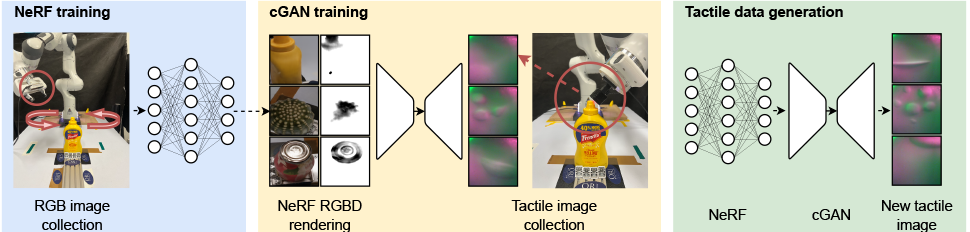
Experiments were first performed in simulation as proof-of-concept and then in the real world to test the hypothesis that generated tactile data can improve performance on downstream robotics tasks. To collect tactile images, the ORI employed Digit tactile sensors [11] - which have two main components - an RGB camera and a compliant layer made of a soft gel. As a working principle, the camera captures the deformations of the soft gel caused by contact forces. To train NeRF models for each of the 27 simulation objects, the team collected 48 images per object taken from evenly sampled poses around a sphere centered on the object. To obtain tactile readings, a constant force is applied to the simulated Digit sensor, with the objects fixed. Typically 500 tactile readings are collected for each object, and correspondingly 500 RGB-D images were synthesised from the NeRF model for each object, using the sensor orientation as the view orientation. The rendered RGB-D images were then preprocessed and paired with their corresponding tactile images for training the cGAN model. For the nine real world objects, 118 camera images were taken per object for training the NeRF model. Meanwhile, to collect tactile data, 132 touches were performed per object and 50 frames were performed per touch. After discarding cases where no tactile readings are obtained, the resultant real-world training dataset contains 398 touches and 19,900 frames.
Project Results
Following training of the model using the simulation and real-world datasets, the system was evaluated on novel objects in both simulated and real-world environments, as demonstrated in the diagram below.
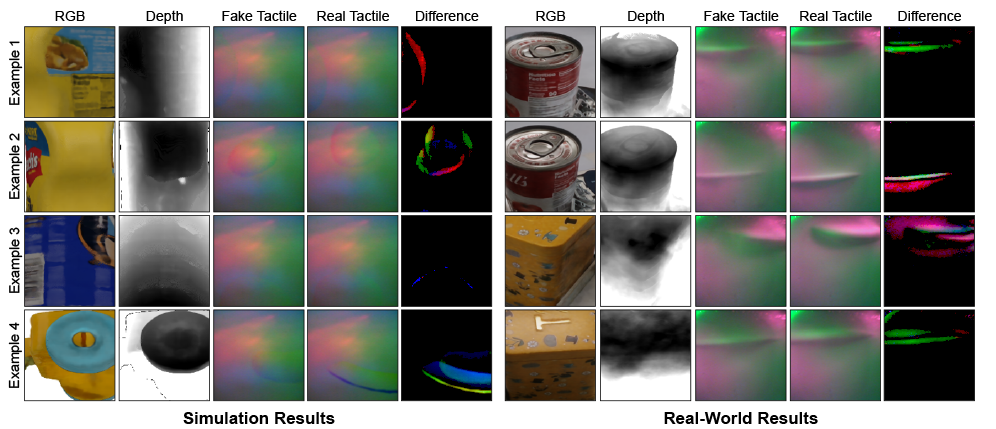
The ORI approach generated faithful tactile images in both simulated (left) and real-world (right) domains on objects it has not seen before in training. The columns show RGB images, depth images, fake tactile images, real tactile images and the difference images between the real and the fake images. To evaluate the quality of the generated tactile images, tactile object classification was used as an example task. By augmenting a given tactile dataset with generated tactile images, it is possible to improve the success rate of the tactile classifier by a large margin. This shows that the proposed generative model is able to generate tactile images useful for the tactile classification task. Through leveraging NeRF models, the team was also able to render additional RGB-D images of the object from novel view angles and generate additional tactile images to further augment the dataset at a low cost.
Furthermore, by using a much smaller fine-tuning dataset than the original RGB-D and tactile training dataset, the ORI team was able to fine-tune a trained cGAN model to adapt to a different sensor with different characteristics. An OmniTact sensor was selected [13] and the corresponding results demonstrate that the generated fake tactile data is qualitatively similar to the real tactile data as seen below.

Conclusions
The new ORI framework leverages NeRF models to render RGB-D images of an object from desired poses and passes the RGB-D images to a cGAN model to generate the desired tactile images. Compared to state of the art, this approach allowed for the generation of tactile images for 3D objects from arbitrary viewpoints, without the need for accurate sensor or object models. The results demonstrate that the generated tactile images are structurally similar to ground-truth images and are useful in downstream robotics tasks such as tactile classification.The new ORI framework leverages NeRF models to render RGB-D images of an object from desired poses and passes the RGB-D images to a cGAN model to generate the desired tactile images. Compared to state of the art, this approach allowed for the generation of tactile images for 3D objects from arbitrary viewpoints, without the need for accurate sensor or object models. The results demonstrate that the generated tactile images are structurally similar to ground-truth images and are useful in downstream robotics tasks such as tactile classification
Further information on these robotic experiments and the results can found by accessing the full white paper here.
References:
[1] R.Calandra, A.Owens, D.Jayaraman, J.Lin, W.Yuan, J.Malik, E.H.Adelson, and S.Levine. More than a feeling: Learning to grasp and regrasp using vision and touch. IEEE Robotics and Automation Letters, 3(4):3300–3307, 2018
[2] Y. Narang, B. Sundaralingam, M. Macklin, A. Mousavian, and D. Fox. Sim-to-real for robotic tactile sensing via physics-based simulation and learned latent projections. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6444–6451, 2021
[3] Z. Kappassov, J.-A. Corrales, and V. Perdereau. Tactile sensing in dexterous robot hands – review. Robotics and Autonomous Systems, 74:195–220, 2015
[4] S. Luo, J. Bimbo, R. Dahiya, and H. Liu. Robotic tactile perception of object properties: A review. Mechatronics, 48:54–67, 2017
[5] J. M. Gandarias, J. M. Gómez-de Gabriel, and A. J. Garcıa-Cerezo. Enhancing perception with tactile object recognition in adaptive grippers for human-robot interaction. Sensors, 18(3), 2018
[6] L. Cao, R. Kotagiri, F. Sun, H. Li, W. Huang, and Z. M. M. Aye. Efficient spatio-temporal tactile object recognition with randomized tiling convolutional networks in a hierarchical fu- sion strategy. Proceedings of the AAAI Conference on Artificial Intelligence, 30(1), Mar. 2016
[7] J.-T. Lee, D. Bollegala, and S. Luo. “Touching to see” and “seeing to feel”: Robotic cross- modal sensory data generation for visual-tactile perception. In 2019 International Conference on Robotics and Automation (ICRA), pages 4276–4282, 2019
[8] Y. Li, J.-Y. Zhu, R. Tedrake, and A. Torralba. Connecting touch and vision via cross-modal prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10609–10618, 2019
[9] S. Cai, K. Zhu, Y. Ban, and T. Narumi. Visual-tactile cross-modal data generation using residue-fusion gan with feature-matching and perceptual losses. IEEE Robotics and Automation Letters, 6(4):7525–7532, 2021
[10] B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM, 65(1): 99–106, dec 2021. ISSN 0001-0782.[11] E. Johns, “Coarse-to-fine imitation learning: Robot manipulation from a single demonstration,” in IEEE International Conference on Robotics and Automation (ICRA), 2021
[11] M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V. R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, D. Jayaraman, and R. Calandra. Digit: A novel design for a low- cost compact high-resolution tactile sensor with application to in-hand manipulation. IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
[12] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros. Image-to-image translation with conditional adversarial networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 5967–5976, 2017
[13] A. Padmanabha, F. Ebert, S. Tian, R. Calandra, C. Finn, and S. Levine. Omnitact: A multi- directional high-resolution touch sensor. In 2020 IEEE International Conference on Robotics and Automation (ICRA), pages 618–624, 2020
The Scan Partnership
Scan has been supporting ORI robotics research as an industrial member since 2020. Scan provides a cluster of NVIDIA DGX and EGX servers and AI-optimised PEAK:AIO NVMe software-defined storage, to further robotic knowledge and accelerate development. This cluster is overlaid with Run:ai cluster management software in order to virtualise the GPU pool across the compute nodes to facilitate maximum utilisation, and to provide a mechanism of scheduling and allocation of ORI workflows’ across the combined GPU resource. Access to this infrastructure is delivered via the Scan Cloud platform, hosted in a secure UK datacentre.
Project Wins
NeRF models passing RGB-D images to cGAN mode, generating the desired tactile images
Generation of tactile images for 3D objects from arbitrary viewpoints possible
Time and cost savings generated due to access to GPU-accelerated cluster

Jun Yamada
Phil student, Applied AI Lab (A2I), ORI
"My experience using the Scan cluster for my research was truly amazing. The computing resources provided by the cluster allowed me to train and test complex, large models at a scale easily. The Scan team is also supportive in helping us navigate any technical issues that arise."

Professor Ingmar Posner
Head of the Applied AI Group, ORI
"We are delighted to have Scan as part of our set of partners and collaborators who are equally passionate about advancing the real-world impact of robotics research. Integral involvement of our technology and deployment partners will ensure that our work stays focused on real and substantive impact in domains of significant value to industry and the public domain."
Speak to an expert
You’ve seen how Scan continues to help the Oxford Robotics Institute further its research into the development of truly useful autonomous machines. Contact our expert AI team to discuss your project requirements.
phone_iphone Phone: 01204 474210
mail Email: [email protected]
Related Content


ORI Embodied Intelligence Project
Five year project to investigate embodied intelligence.
Read More >