Using AI to Advance Robot Learning Case Study

Oxford Robotics Institute
Using AI to Advance Robot Learning
PUBLISHED 2 MAY 2023
The Oxford Robotics Institute (ORI) is built from collaborating and integrated groups of researchers, engineers and students all driven to change what robots can do for us. Their current interests are diverse, from flying to grasping - inspection to running - haptics to driving, and exploring to planning. This spectrum of interests leads to researching a broad span of technical topics, including machine learning and AI, computer vision, fabrication, multispectral sensing, perception and systems engineering.
Efficient Skill Acquisition for Complex Manipulation Tasks in Obstructed Environments
Project Background
The ability for robots to learn new skills using limited supervision is essential for maximising their up-time and productivity. For example, small-batch manufacturing - where there are a limited number of parts to be produced - is an ideal use case scenario that would greatly benefit from efficient skill acquisition. In such a setting, a robot must learn to manipulate new objects while maintaining efficiency in potentially obstructed environments, however, existing methods such as motion planning (MP) and reinforcement learning (RL) struggle to satisfy the requirements to facilitate this capability.
MP [1-3] can generate collision-free paths capable of guiding a robot safely in obstructed environments if a detailed state of the environment and outcome are specified. However, MP is not designed for cases where complex manipulation tasks are required or environmental interaction is necessary. On the other hand RL has shown promising outcomes in controlling a robot for complex manipulation tasks such as grasping and insertion [5-7], however, previous studies have focussed on simulated environments [8]. Combining MP and RL has been investigated in the past [4, 9], and demonstrates the potential of leveraging the strengths of both methods to solve manipulation tasks in obstructed environments, but the model has required re-training for each new target object.
Project Approach
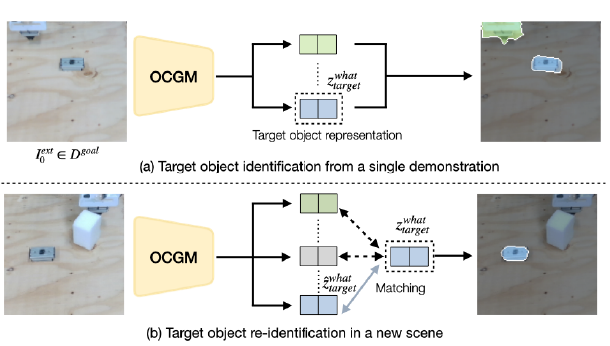
The ORI team proposed a system that leverages an object-centric generative model (OCGM) [10] taking advantage of MP and RL techniques. By identifying a target object from a single human demonstration, an OCGM would be pre-trained on a range of diverse synthetic scenes, leading to robust re-identification of that object in new scenes by matching to its object-centric representation. MP was used to generate a collision-free path to the target object while avoiding obstacles, before a learned RL policy was executed to complete the complex manipulation tasks, and a skill transition network is employed to bridge the gap between terminal states of MP and feasible start states of a sample efficient RL policy.
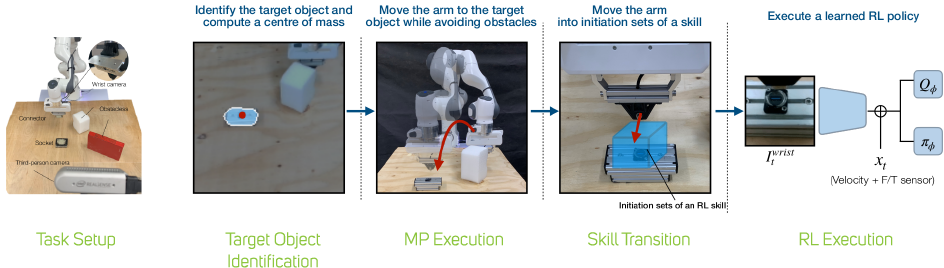
The project involved various distinct elements - firstly, the proposal of a system for efficient skill acquisition in obstructed environments that leverages an OCGM for object-agnostic, one-shot goal specification. Secondly the ORI aimed to show that the OCGM-based one-shot goal specification method achieves comparable accuracy against several goal identification baselines and finally to demonstrate that the system performs significantly better in real-world environments compared to baselines, including a state of the art RL algorithm.
The ORI team chose to evaluate its framework on four assembly tasks commonly found in industry - connections for VGA, RJ45, E-model and USB-A. Each socket is attached to a mount of varying size and colour to demonstrate the versatility and efficiency of our one-shot goal specification using an OCGM.

Project Results
Real-world industrial assembly task were carried out in obstructed environments, with the OCGM used to specify a goal for MP, followed by the skill transition network and a learned RL policy.

As previously highlighted, the performance of the ORI approach was benchmarked against a state of the art RL algorithm and four comparable examples of their approach. These were as follows:
- Soft Actor Critic (SAC) - the RL algorithm trained with 25 demonstrations using FERM [6]
- MP + Demonstration Replay - substitutes replaying a single expert demonstration for the learned RL policy execution in our method, inspired by previous work [11]
- MP + BC - replaces the learned RL policy in our method with Behaviour Cloning (BC) [12], [13], trained from 25 demonstrations
- MP + Heuristic - uses a manually designed heuristic policy [9] instead of the learned RL policy in our method to solve the task
- MP + RL - the ORI method but without no skill transition network for comparison
- MP + RL - the ORI method
The below table shows the various success rates of each approach from an average of over 30 trials and a confidence interval of 95%.
| Success Rates | ||||
|---|---|---|---|---|
| Method | VGA | RJ45 | E-model | USB-A |
| SAC | 0.0% | 0.0% | 0.0% | 0.0% |
| MP + Demonstration Replay | 3.3% | 0.0% | 3.3% | 0.0% |
| MP + BC | 16.7% | 16.7% | 23.3% | 26.7% |
| MP + Heuristic | 10.0% | 16.7% | 36.7% | 43.3% |
| MP + RL (w/o) | 73.3% | 46.7% | 80.0% | 70.0% |
| MP + RL (ORI) | 86.7% | 83.3% | 93.3% | 96.7% |
Conclusions
The experimental results show that the ORI method for one-shot goal identification provides competitive accuracy to other baseline approaches and that the modular framework outperforms competitive baselines, including a state of the art RL algorithm, by a significant margin for complex manipulation tasks in obstructed environments. In addition, this method successfully solves real-world industrial insertion tasks in obstructed environments from fewer demonstrations. In future work the team plan to investigate more advanced settings, such as randomising the socket orientation.
Further information on these robotic experiments and the results can found by accessing the full white paper here.
References
[1] N.M.Amatoand, Y.Wu,“A randomized road map method for path and manipulation planning,” in IEEE International Conference on Robotics and Automation, 1996
[2] S. M. LaValle, “Rapidly-exploring random trees: A new tool for path planning,” Computer Science Department, Iowa State University, Tech. Rep. TR 98-11, 1998
[3] S. Karaman and E. Frazzoli, “Sampling-based algorithms for optimal motion planning,” International Journal of Robotics Research, vol. 30, no. 7, pp. 846–894, 2011
[4] M. A. Lee, C. Florensa, J. Tremblay, N. Ratliff, A. Garg, F. Ramos, and D. Fox, “Guided uncertainty-aware policy optimization: Combining learning and model-based strategies for sample-efficient policy learn- ing,” IEEE International Conference on Robotics and Automation, 2020
[5] D. Kalashnikov, A. Irpan, P. Pastor, J. Ibarz, A. Herzog, E. Jang, D. Quillen, E. Holly, M. Kalakrishnan, V. Vanhoucke et al., “Scalable deep reinforcement learning for vision-based robotic manipulation,” in Conference on Robot Learning, 2018, pp. 651–673
[6] A. Zhan, P. Zhao, L. Pinto, P. Abbeel, and M. Laskin, “A framework for efficient robotic manipulation,” arXiv preprint arXiv:2012.07975, 2020
[7] J. Luo, O. Sushkov, R. Pevceviciute, W. Lian, C. Su, M. Vecerik, N. Ye, S. Schaal, and J. Scholz, “Robust multi-modal policies for industrial assembly via reinforcement learning and demonstrations: A large-scale study,” arXiv preprint arXiv:2103.11512, 2021
[8] T.Haarnoja, A.Zhou, P.Abbeel, and S.Levine,“Soft actor-critic: Off- policy maximum entropy deep reinforcement learning with a stochastic actor,” in International Conference on Machine Learning, 2018
[9] J. Yamada, Y. Lee, G. Salhotra, K. Pertsch, M. Pflueger, G. S. Sukhatme, J. J. Lim, and P. Englert, “Motion planner augmented reinforcement learning for obstructed environments,” in Conference on Robot Learning, 2020
[10] Y. Wu, O. P. Jones, M. Engelcke, and I. Posner, “Apex: Unsupervised, object-centric scene segmentation and tracking for robot manipulation,” in 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 3375–3382
[11] E. Johns, “Coarse-to-fine imitation learning: Robot manipulation from a single demonstration,” in IEEE International Conference on Robotics and Automation (ICRA), 2021
[12] T. Zhang, Z. McCarthy, O. Jow, D. Lee, X. Chen, K. Goldberg, and P. Abbeel, “Deep imitation learning for complex manipulation tasks from virtual reality teleoperation,” in IEEE International Conference on Robotics and Automation, 2018, pp. 5628–5635
13] M. Bojarski, D. D. Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, X. Zhang, J. Zhao, and K. Zieba, “End to end learning for self-driving cars,” arXiv preprint arXiv:1604.07316, 2016
The Scan Partnership
Scan has been supporting ORI robotics research as an industrial member since 2020. Scan provides a cluster of NVIDIA DGX and EGX servers and AI-optimised PEAK:AIO NVMe software-defined storage, to further robotic knowledge and accelerate development. This cluster is overlaid with Run:ai cluster management software in order to virtualise the GPU pool across the compute nodes to facilitate maximum utilisation, and to provide a mechanism of scheduling and allocation of ORI workflows’ across the combined GPU resource. Access to this infrastructure is delivered via the Scan Cloud platform, hosted in a secure UK datacentre.
Project Wins
Modular frameworks seen to outperform competitive baselines by a significant margin
Solving of real-world insertion tasks in obstructed environments from fewer demonstrations
Time and cost savings generated due to access to GPU-accelerated cluster

Shaohong Zhong
DPhil student, Applied AI Lab (A2I), ORI
"The Scan clusters have been incredibly useful for my research, which required a significant amount of computational resources. Additionally, the Scan team has consistently offered prompt and helpful support whenever I had any issues or questions. Overall, it has been a fantastic experience using Scan."

Professor Ingmar Posner
Head of the Applied AI Group, ORI
"We are delighted to have Scan as part of our set of partners and collaborators who are equally passionate about advancing the real-world impact of robotics research. Integral involvement of our technology and deployment partners will ensure that our work stays focused on real and substantive impact in domains of significant value to industry and the public domain."
Speak to an expert
You’ve seen how Scan continues to help the Oxford Robotics Institute further its research into the development of truly useful autonomous machines. Contact our expert AI team to discuss your project requirements.
phone_iphone Phone: 01204 474210
mail Email: [email protected]
Related Content


ORI Embodied Intelligence Project
Five year project to investigate embodied intelligence.
Read More >