
Oxford Robotics Institute - Using AI to Advance Robot Learning
Oxford Robotics Institute
Learning to understand objects in images without supervision for robotics applications
PUBLISHED 13 MAY 2021
The Oxford Robotics Institute (ORI) is built from collaborating and integrated groups of researchers, engineers and students all driven to change what robots can do for us. Their current interests are diverse, from flying to grasping - inspection to running - haptics to driving, and exploring to planning. This spectrum of interests leads to researching a broad span of technical topics, including machine learning and AI, computer vision, fabrication, multispectral sensing, perception and systems engineering.
Learning to understand objects in images without supervision for robotics applications
Project Background
Robots need to be able to sense and interpret their surroundings in order to perform their intended tasks. For example, an autonomous car needs to identify other road users in a stream of images from a video camera in order to decide what to do. For applications such as this one, the common approach is to collect a large amount of labelled training examples for relevant objects such as cars, pedestrians, and cyclists in order to train a supervised machine learning model that is able to identify such objects on-the-fly. However, it is fundamentally impossible to collect labelled data for every possible object category that a robot might encounter during its life-time.
For example in manufacturing, you might want to regularly teach the robot how to perform new tasks with components that it might never have seen before. Rather than trying to collect labelled data for every possible situation, it is possible to develop unsupervised methods that are able to identify object-like things in sensory data without labelled supervision. This can be achieved by building knowledge about the world into a machine learning model: objects are typically spatially localised, persist over time without magically disappearing, two objects cannot occupy the same physical space, etc. This knowledge can be used to build machine learning models that are able to discover object-like things without requiring any manual annotations. We need to be aware though that this is an under-constrained problem as objectness is context-dependent: we might view a car as a single object in the context of urban driving, but in terms of manufacturing we would probably want to rather view it as a collection of parts. Ultimately, the ambition is to develop models that are able to choose the level of abstraction that is most appropriate and useful in order for a robot to complete a specific task.
Project Approach
Inspired by prior work on the subject1, ORI was able to formulate such a model as an autoencoder which consists of two parts: an encoder maps in image to a set of latent codes where each code describes a single object in an image and the decoder maps these codes back to an image. The encoder and decoder can be parameterised by neural networks and the model can be trained by learning to reconstruct a set of training images via these object-centric latent codes. The exact formulation of this autoencoder allows development of different capabilities, depending on the designated application of the model. For example, the encoder and/or the decoder can be formulated so as to produce a set of segmentation masks that indicate which pixels in an image belong to a certain object2. Moreover, it is also possible to formulate the autoencoder as a generative model which allows it to sample sets of latent codes from a probability distribution in order to generate synthetic images in an object-based fashion3,4. One application of this is to develop a world model in which robots learn new skills by imagining different situations5. The computational requirements for training these types of autoencoders depend on both the complexity of the training data and the exact formulation of the model. For example, some models can be trained on smaller datasets within two days using a single NVIDIA Titan RTX GPU3,4, while for other model formulations and larger datasets training might take up to a week even using eight far more powerful NVIDIA V100 GPUs6
Project Results
This research has led to the development of a novel object-centric generative model (OCGM) which learns to segment objects in images without labelled supervision while also being able to generate synthetic images in an object-by-object fashion. The model has been called GENESIS (GENErative Scene Inference and Sampling)3 and more recently an improved model has been developed - GENESIS-V24, which achieves better performance on both synthetic datasets as well as real-world datasets.
For example, Figure 1 shows the image reconstructions and segmentations after training GENESIS-V2 on the ShapeStacks dataset7, which shows rendered images of a 3D environment that contains simulated block towers. It can be seen that GENESIS-V2 learns to cleanly segment the individual blocks without requiring any labelled supervision. Figure 2 shows the same type of results after training GENESIS-V2 on the ObjectsRoom dataset8, which shows different types of objects in a square room from various vantage points.

Figure 1: Reconstructions and segmentations after training GENESIS-V2 on the ShapeStacks dataset.
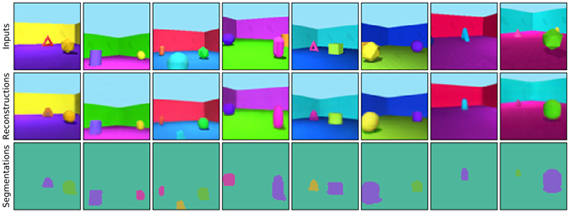
Figure 2: Reconstructions and segmentations after training GENESIS-V2 on the ObjectsRoom dataset.
Similarly, Figure 3 shows what happens when training GENESIS-V2 on a more complex real-world dataset that was collected by the MIT-Princeton team for their entry to the 2016 Amazon Picking Challenge9. Even here, the model is able to separate the foreground objects from the background. Nevertheless, the reconstructions are still a bit blurry and the segmentations could also be better, leaving room for improvement for future research. Finally, Figure 4 illustrates the capability of GENESIS-V2 to generate novel images after training on the ObjectsRoom dataset. These images are synthetically generated by the model and look fairly similar to actual images from the training data. Yet, a careful observer is still able to tell apart "real" images and images generated by the model.

Figure 3: Reconstructions and segmentations after training GENESIS-V2 on images from the MIT-Princeton 2016 Amazon Picking Challenge team.

Figure 4: Novel images generated by GENESIS-V2 after training on the ObjectsRoom dataset.
Conclusions
In summary, OCGMs allow us to segment images into object-like entities without labelled supervision and also to generate synthetic images in an interpretable, object-based fashion. In the future, the aim is to further improve these models in terms of reconstruction, segmentation, and generation quality. The idea is also to apply them to increasingly complex datasets so that they can be used them to help robots quickly learn new skills for practical real-world applications.
References
- Attend, Infer, Repeat: Fast Scene Understanding with Generative Models
- MONet: Unsupervised Scene Decomposition and Representation
- GENESIS: Generative Scene Inference and Sampling with Object-Centric Latent Representations
- GENESIS-V2: Learning Unordered Object Representations without Iterative Refinement
- World Models
- Multi-Object Representation Learning with Iterative Variational Inference
- ShapeStacks: Learning Vision-Based Physical Intuition for Generalised Object Stacking
- Multi-Object Datasets
- Multi-view Self-supervised Deep Learning for 6D Pose Estimation in the Amazon Picking Challenge
The Scan Partnership
Scan has been supporting ORI robotics research as an industrial member since 2020. Scan provides a cluster of NVIDIA DGX and EGX servers and AI-optimised PEAK:AIO NVMe software-defined storage, to further robotic knowledge and accelerate development. This cluster is overlaid with Run:ai cluster management software in order to virtualise the GPU pool across the compute nodes to facilitate maximum utilisation, and to provide a mechanism of scheduling and allocation of ORI workflows’ across the combined GPU resource. Access to this infrastructure is delivered via the Scan Cloud platform, hosted in a secure UK datacentre.
Project wins
Object-centric generative model able to segment objects without labelled supervision
Time and cost savings generated due to access to GPU-accelerated cluster

Professor Ingmar Posner
Head of the Applied AI Group, ORI
"Using the Scan cluster, we are able to iterate over multiple learned models in parallel on their dedicated Deep Learning hardware. This translates to more time testing on our real robots, and less time waiting for models to train."

Elan Raja
CEO, Scan
"Being able to support such innovation in the field of robotics makes the Scan team very proud. If our hardware can contribute even a little to shortening the time until these technologies improve human lives, then we see the investment very worthwhile."
Speak to an Expert
You’ve seen how Scan continues to help the Oxford Robotics Institute further its research into the development of truly useful autonomous machines. Contact our expert AI team to discuss your project requirements.

