
NVIDIA EGX Custom Inferencing and Retraining Systems
High Performance Inferencing and Retraining Solutions
Inferencing
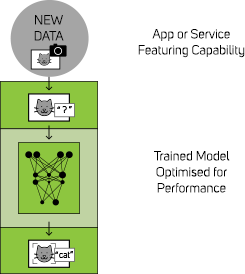
Inferencing is the process of taking a previously trained deep learning model and deploying it onto a device, which will then process incoming data (such as text, images or video) to look for and identify whatever it has been trained to recognise. Many of these devices are very small embedded units that do not require a lot of compute performance and are designed to sit on the network edge, say on a production line or amongst a smart city environment. Alternatively, if speed is of the essence or datasets particularly large then the device may be a server with regular PCIe GPU cards installed, much like a server designed for training although the models of GPU are likely to differ and be ones aimed at inferencing performance.
Retraining
Following deployment of a trained AI model the intention is that edge-based inferencing hardware will then carry out the intended task of the model, whether this be to identify structural defects in a manufacturing process, monitor traffic flow across a smart city environment or carry out security surveillance in an airport. Although the intention of any AI model is to exceed human capability (96% accuracy or higher), changes in the materials or subjects being monitored may require retraining of the AI model. Rather than the original training phase needing huge GPU-accelerated compute resource such as NVIDIA DGX systems, this retraining phase is usually minor tweaking to a model so this kind of power is not required.
High Performance Inferencing and Retraining
Using a custom inferencing or retraining system for deep learning and AI workloads gives you the ultimate control. You have full control over the specification for your projects but you can also build in flexibility as required. A system can be configured so that no resources are under utilised, or a larger chassis can be partially populated at purchase leaving space for scaling at a later date. The choice is yours.

NVIDIA GPU Accelerators
The NVIDIA Ampere family of GPU accelerator cards represents the cutting edge in performance for all AI workloads, offering unprecedented compute density, performance and flexibility. There are a number of models that excel at both inferencing and retraining scenarios, whereas some others would be focussed purely at the inference side of things.
Inferencing and Retraining
H100 PCIe Gen 5
A100 PCIe Gen 4
L40 PCIe Gen 4
A30 PCIe Gen 4
Inferencing Only
A10 PCIe Gen 4
L4 PCIe Gen 4
A2 PCIe Gen 4
Host CPUs
You also have a wide choice of host CPUs available, AMD EPYC or Intel Xeon. Our system architects can recommend which of these is best for your requirements and whether one or two CPUs is required.


System Memory
Depending on the type of workload, a large amount of system memory may have less or more relevance than GPU memory, but with a custom training server memory capacity can be tailored to your needs. Additionally, a bespoke server allows for simple future memory expansion is required.NVIDIA recommends at least double the amount of system RAM as GPU RAM, so high-end systems may scale into the TBs. Additionally Intel Xeon based servers can make use of a combination of traditional DIMMs and Intel Persistent Optane Memory DIMMs, allowing a flexible solution addressing performance, fast caching and extra storage capacity.

Internal Storage
Storage within a training server is also a very personal choice - it may be that a few TB of SSD capacity are enough for datasets for financial organisations where a large volume of files is still relatively small. Alternatively, image-based datasets may be vast, so there is never any real option of using internal storage and a separate fast flash storage array is the way to go. If this is thecase, internal SSD cost can be minimised and this remaining budget used elsewhere. Flexibility and performance can also be gained by choosing M.2 formats, NVMe connectivity or Optane options. as required.
Networking
Depending on whether connectivity is needed to a wider network, or an external flash storage array, networking interfaces and speeds can be customised to suit. Ethernet or Infiniband options are available up to 400Gb/s in speed, both providing powerful CPU offloading to maximise performance, and minimise latency.
Additionally, advanced NVIDIA BlueField Data Processing Unit (DPU) NICs can be specified where the highest performance is required, as these cards not only include networking functionality but also accelerate software management, security and storage services by offloading these tasks from the CPU.
Chassis
From 2U compact servers up to 4U expandable systems, chassis choice is key dependant upon whether space saving is the key factor or scalability is required. As a custom server can be partially populated, a larger chassis can be chosen with a view to expandability in the future. Additionally, both air cooled and liquid cooled server systems are available.

Our intuitive online configurators provide complete peace of mind when building your inferencing or retraining server, alternatively speak directly to one of our friendly system architects.